Quick Definition (30–60 words)
Behavioral biometrics identifies users by how they interact with systems—typing rhythm, mouse movement, touch gestures, device handling—rather than by what they are. Analogy: it’s like recognizing a driver by their steering habits instead of their face. Formally: probabilistic behavioral pattern recognition used for continuous authentication and fraud detection.
What is Behavioral Biometrics?
Behavioral biometrics is the science and engineering practice of using observable user behavior patterns to identify, authenticate, or risk-score users. It is NOT a static biometric like fingerprints or iris scans; it focuses on dynamic interaction signals and temporal patterns.
Key properties and constraints:
- Probabilistic and adaptive: Models output likelihoods, not certainties.
- Privacy-sensitive: Data often considered highly sensitive; anonymization and differential privacy matter.
- Device and context dependent: Signals vary across devices, OS versions, and environments.
- Latency and compute trade-offs: Real-time decisions require lightweight edge inference or optimized streaming pipelines.
- Drift and retraining: User behavior evolves; models need continuous calibration.
Where it fits in modern cloud/SRE workflows:
- Edge inference for low-latency scoring (CDN edge, mobile SDKs).
- Streaming pipelines in cloud for feature extraction and model updates.
- Integration with identity and access management (IAM) and fraud detection services.
- Observability and SLOs around model availability, false-positive rates, and scoring latency.
- Automation for model retraining and canary deployments.
Text-only diagram description (visualize):
- Devices generate raw interaction events (keystrokes, mouse, touch, sensors).
- Edge SDKs preprocess events and compute local features.
- Features stream to cloud ingestion (message queue).
- Feature store holds time-series feature windows per user.
- Real-time scorer (edge or service) computes risk scores against behavioral models.
- Decision service applies policy (allow, step-up, block) and logs outcome to SIEM and observability.
- Offline training pipeline consumes labeled events and feedback to update models.
- Model registry and CI/CD for ML deploys updated models to edge and cloud.
Behavioral Biometrics in one sentence
Behavioral biometrics uses patterns in user interactions to continuously authenticate or risk-score users in a probabilistic, privacy-aware manner.
Behavioral Biometrics vs related terms (TABLE REQUIRED)
| ID | Term | How it differs from Behavioral Biometrics | Common confusion |
|---|---|---|---|
| T1 | Physiological Biometrics | Uses physical traits not behavior | Often conflated as both being biometrics |
| T2 | Keystroke Dynamics | Subset focused on typing patterns | Mistaken as entire field |
| T3 | Continuous Authentication | Broader goal that may use behavioral signals | Treated as a separate technology |
| T4 | Fraud Detection | Uses many signals not just behavior | Assumed to be identical |
| T5 | Device Fingerprinting | Uses device artifacts not user behavior | Confused with behavioral signatures |
| T6 | Risk Scoring | Higher-level decision output | Not a data source but an outcome |
| T7 | Keystroke Latency | Specific metric not whole system | Mistaken as comprehensive |
| T8 | Behavioral Analytics | Business analytics using behaviors | Mistaken as authentication tech |
| T9 | Anomaly Detection | Algorithmic approach, not domain-specific | Assumed equivalent |
| T10 | Biometric Authentication | Often physical biometrics | Thought to always be physiological |
Row Details (only if any cell says “See details below”)
- None
Why does Behavioral Biometrics matter?
Business impact:
- Revenue protection: Reduces fraud losses by detecting account takeover and automated attacks, lowering chargebacks and remediation costs.
- Trust and retention: Low-friction continuous authentication improves user experience and reduces abandonment.
- Regulatory risk reduction: Helps satisfy fraud monitoring and identity-proofing requirements in regulated industries.
Engineering impact:
- Incident reduction: Automated behavioral detection can reduce manual investigation load.
- Velocity: Integrating behavioral scoring reduces false positives in rule engines, enabling safer automation.
- Cost: Requires compute for streaming and model training but can reduce downstream costs by preventing fraud.
SRE framing:
- SLIs: scoring latency, model availability, false-positive rate, false-negative rate.
- SLOs: e.g., 99.9% scorer availability, false-positive SLOs calibrated to business risk.
- Error budget: Allow model updates and retraining within error budget burn-rate limits.
- Toil: Manual review workflows for flagged users are toil-heavy; automation should be prioritized.
- On-call: Include ML/SRE engineers for model-serving incidents and feature store availability.
What breaks in production (realistic examples):
- Latency spike in scorer causing step-up auth for many users.
- Model drift increasing false positives after a new OS release changes touch patterns.
- Data pipeline lag causing stale features and misclassification.
- Privacy complaint due to improperly stored raw event logs.
- Canary deployment rolling out a model with high false negatives letting fraud through.
Where is Behavioral Biometrics used? (TABLE REQUIRED)
| ID | Layer/Area | How Behavioral Biometrics appears | Typical telemetry | Common tools |
|---|---|---|---|---|
| L1 | Edge Application | SDK computes local features and scores | Event rates CPU latency | Mobile SDKs SDK logs |
| L2 | Network/Proxy | Bot detection via request patterns | Request headers anomalies | WAFs CDN logs |
| L3 | Service Backend | Real-time scoring microservice | Score latency error rates | Model server metrics |
| L4 | Data Platform | Feature store and streaming ETL | Lag throughput retention | Kafka metrics feature-store |
| L5 | IAM | Adaptive access policies use scores | Auth events step-up counts | SIEM IAM logs |
| L6 | Observability | Dashboards and alerts for models | SLI/SLO metrics traces | Monitoring platforms |
| L7 | CI/CD & MLOps | Model release pipelines and tests | Deployment success rate | CI metrics model registry |
| L8 | Serverless | Lightweight scoring lambdas | Invocation latency cost | Serverless traces |
| L9 | Kubernetes | Containerized model servers | Pod restarts CPU memory | K8s metrics logging |
| L10 | Compliance/Data | Audit trails and data retention | Audit logs access events | DLP and governance |
Row Details (only if needed)
- None
When should you use Behavioral Biometrics?
When it’s necessary:
- High-value accounts or transactions where continuous authentication reduces fraud.
- Environments with frequent credential stuffing or ATO (account takeover) attacks.
- Regulatory contexts requiring behavioral monitoring for risk scoring.
When it’s optional:
- Low-value consumer apps where password auth with 2FA suffices and budget is limited.
- When user devices are highly uniform and signals add minimal differentiation.
When NOT to use / overuse it:
- As sole proof of identity for high-risk transactions.
- Where collecting behavioral data violates privacy laws or user consent.
- When the operational overhead outweighs risk reduction (small user base, low fraud).
Decision checklist:
- If high-fraud risk AND available event telemetry -> implement behavioral scoring.
- If privacy constraints OR legal restrictions -> choose privacy-preserving options or avoid.
- If latency-critical path AND edge inference unavailable -> use server-side scoring with caching.
- If team lacks ML ops maturity -> start with simple heuristics and staged ML adoption.
Maturity ladder:
- Beginner: Simple rules plus keystroke/typing templates; offline analysis.
- Intermediate: Real-time scoring microservice, feature store, A/B testing.
- Advanced: Edge model inference, continuous learning, federated learning, differential privacy.
How does Behavioral Biometrics work?
Step-by-step components and workflow:
- Data collection: Capture raw interaction events on client (timestamps, positions, sensor data).
- Local preprocessing: Noise filtering, normalization, sessionization.
- Feature extraction: Time intervals, velocities, pressure metrics, derived behavioral vectors.
- Feature storage: Short-term feature windows in a feature store; long-term metrics in analytics store.
- Model scoring: Real-time model inference returns risk score or classification.
- Decisioning: Policy engine applies actions (allow, step-up, block) and logs outcome.
- Feedback loop: Ground-truth labels from fraud investigations and user actions feed retraining.
- Model lifecycle: Model evaluation, canary deployment, rollback, and monitoring.
Data flow and lifecycle:
- Raw event -> edge SDK -> event queue -> preprocess -> feature store -> real-time scorer -> decision -> logs -> offline training consumes labeled logs -> updated model -> deploy.
Edge cases and failure modes:
- Sparse data for new users resulting in low-confidence scores.
- Bot mimicry that approximates human patterns.
- Cross-device user behavior change (desktop to mobile).
- Privacy constraints limiting retention and model accuracy.
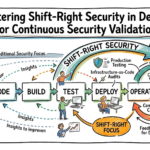
Typical architecture patterns for Behavioral Biometrics
- Edge-First Pattern: Lightweight models run in mobile SDKs for immediate scoring. Use when low latency and privacy are priorities.
- Hybrid Edge-Cloud: Local feature extraction with cloud scoring for heavy models. Use when rich models are needed but some latency tolerated.
- Cloud-Centric Streaming: All scoring occurs in cloud; client sends events. Use for centralized control and simpler clients.
- Serverless Microservices: Small scoring functions invoked per session. Use for bursty workloads and lower operational overhead.
- Federated Learning: Model training across devices without centralizing raw events. Use where privacy constraints are strict.
- Embedded Device Sensors: Combine hardware sensors (accelerometer, gyroscope) with behavioral models for device handling signals.
Failure modes & mitigation (TABLE REQUIRED)
| ID | Failure mode | Symptom | Likely cause | Mitigation | Observability signal |
|---|---|---|---|---|---|
| F1 | High false positives | Many legitimate users step up | Model drift or biased training | Retrain with recent labels adjust threshold | Rising step-up rate |
| F2 | High false negatives | Fraud slips through | Underfitting or missing features | Add features improve labels ensemble models | Increased fraud incidents |
| F3 | Latency spikes | Auth flows timeout | Scorer overloaded or network | Autoscale cache scores degrade heavy models | Sudden scorer latency jump |
| F4 | Data pipeline lag | Stale features used | Backpressure or storage issues | Backfill pipeline add retries alerting | Feature lag metrics |
| F5 | Privacy breach | Sensitive raw logs exposed | Misconfigured retention or logging | Encrypt mask minimize retention | Unexpected data exports |
| F6 | Model rollback loop | Frequent rollbacks | Canary test failures or high burn rate | Harden canary use gradual rollouts | Deployment failure rate |
| F7 | Sparse user signal | Low confidence scores | New users or short sessions | Use fallback auth combine signals | Low-score rate metric |
| F8 | SDK incompatibility | Missing events from clients | Version mismatch or permissions | Version gating clear upgrade path | Client error logs |
| F9 | Adversarial mimicry | Bots mimic humans | Attackers adapt behavior | Use ensemble detection device signals | Small uptick in sophisticated bots |
| F10 | Cost overrun | Cloud costs spike | Unoptimized feature retention inference cost | Optimize features batch scoring spot instances | Cost per million scores |
Row Details (only if needed)
- None
Key Concepts, Keywords & Terminology for Behavioral Biometrics
Authentication vector — A modality used to identify a user such as typing patterns — Matters for choosing signals — Pitfall: assuming single vector is sufficient Adaptive authentication — Dynamic control of auth level based on risk score — Important for UX and security — Pitfall: too aggressive leads to churn Anomaly detection — Identifying deviations from expected behavior — Core technique — Pitfall: high false positives Artifact binding — Linking behavioral signals to a device or session — Enables continuity — Pitfall: weak binding can be spoofed Behavioral template — Stored pattern representing user behavior — Basis for matching — Pitfall: stale templates Bot detection — Identifying automated actors via patterns — Key use case — Pitfall: advanced bots mimic humans Canary deployment — Gradual model rollout to limit blast radius — Best practice for models — Pitfall: skipping canaries leads to rollbacks Classifier calibration — Adjusting model output probabilities — Helps decision-making — Pitfall: miscalibrated scores mislead policies Continuous authentication — Ongoing verification during a session — UX-friendly — Pitfall: privacy and battery impact Data minimization — Collecting only necessary data — Privacy principle — Pitfall: reduces model performance if over-applied Differential privacy — Technique to limit re-identification risk in models — Important for compliance — Pitfall: complexity and utility loss Drift detection — Detecting shifts in data distribution — Critical for model health — Pitfall: ignoring drift increases errors Edge inference — Running models on client devices — Lowers latency — Pitfall: device fragmentation Ensemble models — Combining multiple models to improve accuracy — More robust — Pitfall: operational complexity False positive rate (FPR) — Fraction of legitimate users flagged — Business impact metric — Pitfall: high FPR hurts UX False negative rate (FNR) — Fraction of attackers missed — Security metric — Pitfall: focusing only on FPR Feature store — Centralized repository for model features — Enables consistency — Pitfall: single point of failure Feature engineering — Creating informative input features — Determines model power — Pitfall: overfitting Federated learning — Training across devices without centralizing raw data — Privacy-preserving option — Pitfall: more complex orchestration Fingerprinting — Using device artifacts for identification — Complementary signal — Pitfall: privacy concerns Ground truth labeling — Definitive labels used for supervised training — Essential for model accuracy — Pitfall: label noise Hysteresis — Smoothing decisions over time to avoid flapping — Reduces false alerts — Pitfall: delays in blocking real fraud Incremental learning — Continuous model updates with new data — Reduces lag — Pitfall: untested updates can degrade quality Latency budget — Acceptable time for scoring — Drives architecture — Pitfall: exceeding budget affects UX Lifecycle management — Model versioning, CI/CD, rollback — Operational readiness — Pitfall: ad hoc deployments MAU skew — Behavioral changes by infrequent users — Affects baselines — Pitfall: treating infrequent users same as heavy users Model explainability — Ability to explain why a score occurred — Compliance and trust — Pitfall: opaque models in regulated domains Model registry — Tracks models and metadata — Governance tool — Pitfall: missing lineage for audits Noise filtering — Removing irrelevant events — Improves signal quality — Pitfall: over-filtering loses signal On-device sensors — Hardware signals like accelerometer — Rich signals for device handling — Pitfall: sensor permissions One-class models — Models trained only on legitimate behavior — Useful for anomaly detection — Pitfall: poor specificity Policy engine — Decision component mapping score to action — Business rules hub — Pitfall: brittle rule complexity Privacy-preserving analytics — Aggregation and anonymization methods — Compliance enabler — Pitfall: reduces granularity Reproducibility — Ability to recreate model training and results — Required for audits — Pitfall: missing seed/version control Replay attacks — Attack where recorded behavior is replayed — Security threat — Pitfall: insufficient liveness detection Risk score — Numeric output representing likelihood of fraud — Central to decisioning — Pitfall: misinterpreting threshold semantics Sessionization — Grouping events into sessions — Important for temporal features — Pitfall: wrong session boundaries Telemetry enrichment — Augmenting events with context (IP, geo) — Improves accuracy — Pitfall: PII risk Time-window features — Aggregations over recent windows — Capture temporal context — Pitfall: window too short or long Training/serving skew — Differences between training and real data — Degrades model — Pitfall: not monitoring skew Transfer learning — Reusing pre-trained models for new users — Accelerates adoption — Pitfall: negative transfer Trust score — Business-level aggregated risk metric — Used in policy decisions — Pitfall: mixing unrelated signals
How to Measure Behavioral Biometrics (Metrics, SLIs, SLOs) (TABLE REQUIRED)
| ID | Metric/SLI | What it tells you | How to measure | Starting target | Gotchas |
|---|---|---|---|---|---|
| M1 | Score latency | Time to compute a risk score | P95 scorer response time ms | P95 < 200 ms | Mobile networks vary |
| M2 | Scorer availability | Service uptime for model server | Successful responses over total | 99.9% | Deployments can reduce availability |
| M3 | False positive rate | Legitimate users flagged | FP / total legit auths | < 0.5% initial | Trade-off with FNR |
| M4 | False negative rate | Fraud missed by model | FN / total frauds | < 5% initial | Needs labeled fraud data |
| M5 | Step-up rate | Extra auth prompts triggered | Step-ups / total sessions | Business specific | UX sensitive |
| M6 | Model drift metric | Distribution change score | KL divergence or population shift | Track baseline trend | Choose threshold carefully |
| M7 | Feature freshness | Lag between event and feature use | Median feature pipeline lag s | < 60s for real-time | Streaming complexity |
| M8 | Training to serving skew | Input distribution difference | L1 distance per feature | Small change tolerated | Monitor per-feature |
| M9 | Label latency | Time to acquire ground truth | Median time from event to label days | < 3 days | Investigations are slow |
| M10 | Cost per million scores | Operational cost efficiency | Cloud cost normalized | Business target | Batch scoring cheaper |
| M11 | Model rollout failure rate | Percent of rollbacks | Rollbacks / deployments | < 1% | Canary testing reduces risk |
| M12 | User complaint rate | Users reporting auth issues | Complaints / MAU | Minimal | Subjective metric |
| M13 | Detection lead time | Time between attacker action and detection | Median detection delay s | < 300s | Depends on telemetry |
| M14 | Replay detection rate | Ability to detect recorded attacks | Detected replays / total replays | High as possible | Hard to benchmark |
| M15 | Privacy incidents | Data exposures count | Incidents per period | Zero | Requires governance |
Row Details (only if needed)
- None
Best tools to measure Behavioral Biometrics
(Select 5–10 tools; each tool section follows format)
Tool — Prometheus + Grafana
- What it measures for Behavioral Biometrics: scorer latency, availability, pipeline metrics.
- Best-fit environment: Kubernetes, microservices, cloud-native stacks.
- Setup outline:
- Instrument scorer with metrics endpoints.
- Export feature store and ingestion metrics.
- Configure Grafana dashboards with SLI panels.
- Alert on P95 latency and error rates.
- Strengths:
- Flexible open-source ecosystem.
- Powerful visualization and alerting.
- Limitations:
- Requires effort to instrument ML-specific signals.
- Not specialized for model evaluation.
Tool — Datadog
- What it measures for Behavioral Biometrics: end-to-end traces, logs, metrics for scoring and inference.
- Best-fit environment: Cloud-native, multi-cloud.
- Setup outline:
- Instrument APM for model servers.
- Ingest custom metrics for FPR/FNR.
- Correlate traces and logs for incidents.
- Strengths:
- Unified observability and advanced dashboards.
- Managed service reduces ops overhead.
- Limitations:
- Cost at scale.
- May need custom ML integrations.
Tool — Seldon Core / KFServing
- What it measures for Behavioral Biometrics: model serving metrics and canary traffic splitting.
- Best-fit environment: Kubernetes ML inference.
- Setup outline:
- Deploy model server with Seldon.
- Configure canary routing and metrics export.
- Integrate with Prometheus for SLIs.
- Strengths:
- Designed for model deployments and traffic control.
- Limitations:
- K8s operational overhead.
Tool — Kafka + ksqlDB
- What it measures for Behavioral Biometrics: streaming event rates, feature pipeline lag.
- Best-fit environment: streaming ETL pipelines.
- Setup outline:
- Ingest raw events into Kafka.
- Use ksqlDB for streaming feature derivation.
- Monitor consumer lag metrics.
- Strengths:
- Low-latency streaming and durable logs.
- Limitations:
- Requires ops expertise.
Tool — OpenTelemetry
- What it measures for Behavioral Biometrics: distributed traces and structured events across services.
- Best-fit environment: polyglot microservices.
- Setup outline:
- Instrument SDKs with OTLP.
- Export to chosen backend.
- Tag traces with model version and user id hash.
- Strengths:
- Standardized telemetry.
- Limitations:
- Needs integration into model serving stack.
Recommended dashboards & alerts for Behavioral Biometrics
Executive dashboard:
- Panels: overall fraud rate trend, business impact metrics (revenue saved), average step-up rate, model availability.
- Why: provides leadership KPIs and business context.
On-call dashboard:
- Panels: score latency P50/P95/P99, scorer errors, pipeline lag, recent rollouts, top users by step-ups.
- Why: focused on operational health to triage incidents.
Debug dashboard:
- Panels: per-feature distributions, training vs serving skew, per-model confusion matrices, recent labeled incidents.
- Why: deep-dive for ML engineers during troubleshooting.
Alerting guidance:
- Page vs ticket: Page on scorer availability outages and rapid burn-rate spikes in false positives; ticket for gradual drift warnings and non-urgent model degradations.
- Burn-rate guidance: If false positive rate burns more than 2x expected in short window, escalate and consider rollback.
- Noise reduction tactics: dedupe alerts by user/session, group alerts by model version, use suppression windows during deployments.
Implementation Guide (Step-by-step)
1) Prerequisites – Consent framework and legal review. – Telemetry pipeline baseline (events, queues). – Feature store and model registry. – CI/CD for ML components.
2) Instrumentation plan – Define event schema and sessionization. – Implement client SDKs with versioning. – Ensure minimal PII and hashing where needed.
3) Data collection – Collect keystroke, touch, mouse, sensor events with timestamps. – Enrich with context: IP, device fingerprint, app version. – Apply local noise filtering and batching.
4) SLO design – Choose SLIs from measurement table. – Define SLOs with stakeholder risk/UX trade-offs.
5) Dashboards – Implement executive, on-call, debug dashboards. – Visualize per-model and per-feature metrics.
6) Alerts & routing – Pager for availability and large burn events. – Ticketing for drift notifications and label backlog.
7) Runbooks & automation – Document step-by-step for model rollback, retrain, and canary investigations. – Automate retraining triggers based on drift thresholds.
8) Validation (load/chaos/game days) – Load test scorer at expected peak plus margin. – Chaos test feature store and model serving. – Run game days simulating fraud spikes.
9) Continuous improvement – Weekly review of labeled incidents. – Monthly model performance audits. – Quarterly privacy compliance checks.
Checklists
Pre-production checklist:
- Legal and privacy sign-off obtained.
- Event schema finalized and SDK tested.
- Feature pipeline latency benchmarks met.
- Initial model baseline tested on holdout.
- Runbook and rollback plan in place.
Production readiness checklist:
- Canary deploy plan and gating thresholds set.
- Observability dashboards ready and alerts configured.
- Labeling workflow and feedback loop established.
- Cost and autoscaling policies set.
Incident checklist specific to Behavioral Biometrics:
- Verify scorer availability and latency.
- Check model version and recent deployments.
- Inspect feature pipeline lag and backfill status.
- Review recent labeled fraud or user complaints.
- Decide on rollback or threshold adjustment and execute.
Use Cases of Behavioral Biometrics
1) Account Takeover Prevention – Context: High-value banking apps suffer credential stuffing. – Problem: Passwords compromised; attackers authenticate. – Why helps: Detects atypical typing and device handling to step-up auth. – What to measure: FPR, FNR, reduction in ATO incidents. – Typical tools: Mobile SDK, model server, feature store.
2) Transaction Risk Scoring – Context: E-commerce high-value orders. – Problem: Fraudulent purchases bypass static checks. – Why helps: Continuous session scoring flags suspicious checkout behavior. – What to measure: Detection lead time, chargeback reduction. – Typical tools: Real-time scoring, policy engine.
3) Bot Mitigation for Web Apps – Context: Ticketing site being scalped by bots. – Problem: Automated scripts emulate human interactions. – Why helps: Mouse and interaction velocity distinguish bots. – What to measure: Bot detection rate, false positive impact. – Typical tools: CDN/WAF integration, edge models.
4) Step-up Authentication Optimization – Context: UX suffers from too many 2FA prompts. – Problem: Static thresholds trigger unnecessary step-ups. – Why helps: Behavioral scores allow risk-based step-ups. – What to measure: Step-up reduction, login success rate. – Typical tools: IAM policy engines, risk scoring.
5) Insider Threat Detection – Context: Enterprise systems with privileged access. – Problem: Malicious insider activity looks normal on auth metrics. – Why helps: Behavioral deviations over time highlight insider risk. – What to measure: Longitudinal anomaly detection rates. – Typical tools: SIEM integration, long-term feature analytics.
6) Remote Workforce Verification – Context: Distributed employees accessing sensitive systems. – Problem: Device sharing or account misuse. – Why helps: Continuous verification reduces unauthorized access. – What to measure: Session continuity scores, MFA triggers avoided. – Typical tools: Endpoint SDK, SSO integration.
7) Fraud Investigator Triage – Context: Large fraud operations require triage. – Problem: Investigators drown in alerts. – Why helps: Behavioral scores prioritize highest-risk cases. – What to measure: Investigator throughput, false positives flagged. – Typical tools: Case management, score-based routing.
8) Voice and Call Center Fraud Prevention – Context: IVR and support phone lines vulnerable to social engineering. – Problem: Voice clones or impersonation. – Why helps: Call cadence, pause patterns can signal fraud. – What to measure: Detection rate for voice anomalies. – Typical tools: Call analytics, speech behavior models.
9) Continuous Payment Authentication – Context: Card-not-present transactions. – Problem: Fraudsters use stolen payment details. – Why helps: Session behavior at payment time adds signal. – What to measure: Chargeback reduction, detection latency. – Typical tools: Payment gateway hooks, scoring service.
10) Compliance Monitoring – Context: Regulated sectors need risk-based monitoring. – Problem: Need for continuous identity assurance. – Why helps: Provides additional proof of authentication continuity. – What to measure: Audit trail completeness and anomalous events. – Typical tools: Audit logs, compliance dashboards.
Scenario Examples (Realistic, End-to-End)
Scenario #1 — Kubernetes model server for banking login
Context: A bank wants low-latency scoring for login risk on desktop and mobile web. Goal: Reduce account takeovers while minimizing step-ups. Why Behavioral Biometrics matters here: Typing and mouse patterns provide strong signals during login. Architecture / workflow: Client JS collects events -> batches to backend API -> backend forwards features to K8s model servers -> scoring -> IAM policy decides step-up. Step-by-step implementation:
- Define event schema and minimal retention.
- Implement client event collector and server ingestion.
- Deploy model in Seldon on Kubernetes with canary.
- Route 5% traffic to new model, monitor SLIs.
- Use Prometheus/Grafana dashboards for latency and error rates.
- Automate rollback if FPR rises above threshold. What to measure: Score latency, FPR, step-up rate, ATO incidents. Tools to use and why: Seldon for K8s serving, Prometheus for metrics, Kafka for ingestion. Common pitfalls: Client-side clock skew affecting features. Validation: A/B test with controlled fraud injection and game day. Outcome: Reduced ATOs by X% while maintaining step-up within UX target.
Scenario #2 — Serverless scoring for high-traffic checkout (serverless/PaaS)
Context: E-commerce platform with bursty traffic during sales. Goal: Risk-score checkouts with cost-efficient infrastructure. Why Behavioral Biometrics matters here: Mouse path and touch gestures add signal for bots. Architecture / workflow: Client SDK sends lightweight features -> serverless function (cold-start optimized) scores -> policy in gateway applies hold or allow. Step-by-step implementation:
- Implement edge sampling to limit cost.
- Use serverless functions with provisioned concurrency.
- Cache common benign patterns to avoid repeated scoring.
- Log outcomes and feed back labeled fraud. What to measure: Cost per million scores, P95 latency, detection lead time. Tools to use and why: Managed serverless (PaaS), CDN for preflight checks, feature store. Common pitfalls: Cold starts raising latency and causing timeouts. Validation: Load test at 2x peak and simulate fraud wave. Outcome: Maintain sub-200ms P95 and control costs.
Scenario #3 — Incident response and postmortem for model drift
Context: Sudden rise in false positives after new OS update. Goal: Restore normal false-positive rates and find root cause. Why Behavioral Biometrics matters here: Device behavior changed after OS gesture changes. Architecture / workflow: Monitor flagged incidents -> correlate with device app versions -> rollback model canary -> retrain with recent data. Step-by-step implementation:
- Triage using debug dashboard and feature distribution.
- Identify correlated OS versions.
- Stop new model rollout and route traffic to previous model.
- Create dataset including new OS signals.
- Retrain and test before redeploy. What to measure: FPR trend, model version rollout metrics. Tools to use and why: Prometheus, Grafana, model registry. Common pitfalls: Slow label acquisition delaying retrain. Validation: Canary with representative OS versions. Outcome: False positives returned to target and new model accounts for OS changes.
Scenario #4 — Cost vs performance trade-off for continuous scoring
Context: SaaS provider debating continuous per-interaction scoring or periodic scoring. Goal: Balance fraud detection fidelity with cloud cost. Why Behavioral Biometrics matters here: Continuous scoring improves detection but costs more. Architecture / workflow: Hybrid: cheap heuristic at edge for most interactions, periodic full scoring for high-risk events. Step-by-step implementation:
- Baseline detection uplift vs cost for continuous scoring.
- Implement heuristic pre-filter to reduce cloud scoring.
- Route only suspicious sessions for full model inference.
- Measure detection vs cost and iterate. What to measure: Cost per detection, missed fraud rate, average score latency. Tools to use and why: Serverless for burst scoring, Kafka for events. Common pitfalls: Heuristic too permissive letting fraud through. Validation: Simulate fraud patterns to measure economic trade-offs. Outcome: Achieved 75% of detection with 40% of cost.
Common Mistakes, Anti-patterns, and Troubleshooting
- Symptom: Sudden spike in step-ups -> Root cause: model drift after new app release -> Fix: rollback, gather new labeled data, retrain.
- Symptom: High scorer latency -> Root cause: insufficient autoscaling or heavy model -> Fix: optimize model, use faster inference runtime, autoscale.
- Symptom: Many false positives for mobile users -> Root cause: device sensor differences -> Fix: device-specific models or feature normalization.
- Symptom: Missing events from iOS -> Root cause: SDK permissions not requested -> Fix: update SDK and prompt for permissions.
- Symptom: Feature pipeline lag -> Root cause: backpressure in streaming system -> Fix: scale consumers, add retries.
- Symptom: Increased costs after rollout -> Root cause: per-event scoring without sampling -> Fix: add sampling, cache scores, hybrid approach.
- Symptom: Adversarial bot passes checks -> Root cause: relying on single signal -> Fix: use ensemble signals including device and network.
- Symptom: Legal complaint about data usage -> Root cause: unclear consent or retention -> Fix: tighten consent, minimize retention, anonymize.
- Symptom: Model serving errors after deployment -> Root cause: serialization mismatch -> Fix: contract testing and model validation.
- Symptom: Investigators overwhelmed -> Root cause: too many low-signal alerts -> Fix: calibrate thresholds and prioritize by risk.
- Symptom: Training/serving skew -> Root cause: feature computation differs -> Fix: standardize feature code and use feature store.
- Symptom: Lack of labels -> Root cause: no feedback loop -> Fix: create labeling process and incentivize investigators.
- Symptom: False confidence in scores -> Root cause: not calibrating probabilities -> Fix: calibrate with Platt scaling or isotonic regression.
- Symptom: Inconsistent results across devices -> Root cause: sessionization mismatch -> Fix: consistent session handling.
- Symptom: Alert noise from deployments -> Root cause: no suppression windows -> Fix: suppress expected alerts during rollout.
- Symptom: Missing observability for models -> Root cause: metrics not instrumented -> Fix: add SLIs and traces.
- Symptom: Unexplained drift -> Root cause: external event (holiday) -> Fix: annotate events and use contextual features.
- Symptom: Replay attack success -> Root cause: lack of liveness checks -> Fix: add temporal randomness and sensor fusion.
- Symptom: Poor UX due to step-ups -> Root cause: too low threshold -> Fix: raise threshold and add gradual hysteresis.
- Symptom: Data duplication -> Root cause: client retries not idempotent -> Fix: include event IDs and dedupe logic.
- Symptom: Slow model rollout -> Root cause: manual processes -> Fix: automate CI/CD for ML.
- Symptom: Observability blind spots -> Root cause: only measuring infrastructure not ML metrics -> Fix: add model-specific metrics.
- Symptom: Overfitting during training -> Root cause: small labeled dataset -> Fix: regularization and cross-validation.
- Symptom: Compliance audit failure -> Root cause: lack of audit trails -> Fix: log model version and decisions with retention policy.
- Symptom: Inadequate testing for edge cases -> Root cause: missing synthetic scenarios -> Fix: include adversarial test cases.
Best Practices & Operating Model
Ownership and on-call:
- Shared ownership: security, SRE, ML engineers, product, and legal.
- Dedicated on-call rotation for model-serving incidents with escalation to ML team.
Runbooks vs playbooks:
- Runbooks: operational steps for outages and rollbacks.
- Playbooks: decision workflows for fraud investigations and escalation.
Safe deployments:
- Canary and staged rollouts with automatic rollback thresholds.
- Shadow testing of new models for weeks before canary.
Toil reduction and automation:
- Automate labeling workflows, retraining triggers, and deployment pipelines.
- Use feature store to avoid drift between training and serving.
Security basics:
- Encrypt telemetry in transit and at rest.
- Mask PII and use hashing where needed.
- Harden SDKs to avoid exfiltration.
Weekly/monthly routines:
- Weekly: review label backlog, suspicious case sampling.
- Monthly: model performance audit, privacy review, cost review.
- Quarterly: full postmortem of incidents, compliance audit.
What to review in postmortems:
- Timeline of model and deployment changes.
- Feature distribution shifts.
- Label acquisition delays and their impact.
- Decisions made and rollbacks executed.
- Improvement actions and owners.
Tooling & Integration Map for Behavioral Biometrics (TABLE REQUIRED)
| ID | Category | What it does | Key integrations | Notes |
|---|---|---|---|---|
| I1 | SDKs | Collects raw interaction events | App backend feature pipeline | Use versioning and privacy gating |
| I2 | Feature Store | Stores and serves features | Model trainers scoring services | Critical for training-serving parity |
| I3 | Message Queue | Ingests event streams | Consumers model pipeline | Use durable streaming like Kafka |
| I4 | Model Serving | Hosts inference endpoints | Prometheus Grafana CI/CD | K8s or serverless options |
| I5 | Monitoring | Observability for models | Alerts dashboards traces | Measure SLIs and model metrics |
| I6 | Policy Engine | Maps scores to actions | IAM, SSO gateways | Centralizes business rules |
| I7 | Labeling Tool | Human review and label management | Case management fraud teams | Essential for supervised learning |
| I8 | CI/CD for ML | Automates model builds and tests | Model registry deployment pipelines | Supports canary strategies |
| I9 | Privacy Tools | Anonymization differential privacy | Data governance DLP | Required for compliance |
| I10 | CDN/WAF | Edge enforcement and bot blocking | Edge scoring SDKs | Useful for early mitigation |
| I11 | Cost Management | Tracks cost per score | Billing and tagging systems | Helps optimize scoring design |
| I12 | SIEM | Centralized logs and alerts | SOC workflows IAM | For incident correlation |
Row Details (only if needed)
- None
Frequently Asked Questions (FAQs)
What data does behavioral biometrics collect?
It collects interaction events such as keystroke timings, mouse/touch trajectories, sensor readings, and derived features. Collect only what is necessary and consented.
Is behavioral biometrics privacy-friendly?
It can be if designed with minimization, hashing, encryption, and differential privacy, but it is often sensitive and requires legal review.
Can behavioral biometrics be spoofed?
Sophisticated attackers can mimic behavior; mitigation requires multiple signals, liveness checks, and ensemble models.
Does it work across devices?
Behavior varies by device; cross-device models need special handling or device-specific normalization.
How much does it cost to run?
Varies / depends. Costs depend on sampling rate, feature retention, model complexity, and deployment architecture.
Do I need labeled data?
Yes for supervised models. Unsupervised techniques can be used but have different trade-offs.
How quickly can models degrade?
Varies / depends. External events or client updates can cause immediate drift, so continuous monitoring is essential.
Can I run models on-device?
Yes—edge inference reduces latency and privacy exposure but increases SDK complexity.
What are typical SLIs for behavioral biometrics?
Score latency, scorer availability, false positive rate, false negative rate, and feature freshness.
How to choose thresholds?
Start with business-impact aligned thresholds and iterate using A/B tests and cost-benefit analysis.
How to handle new users with no history?
Use population-level models, fallback authentication, or transfer learning strategies.
Are there legal/regulatory issues?
Yes—privacy laws and sector-specific regulations may constrain data collection and retention.
How to integrate with IAM?
Use a policy engine to map risk scores to actions in IAM/SSO flows.
How to prevent data leakage from SDKs?
Minimize data, encrypt, secure telemetry channels, and code sign SDKs.
What is the difference between behavioral biometrics and fraud scoring?
Behavioral biometrics supplies signals; fraud scoring is a broader decision that may include many other signals.
How often should models be retrained?
Varies / depends. Retrain on drift detection or periodic cadence aligned with label availability.
Can behavioral biometrics replace MFA?
Not entirely; it complements MFA and reduces unnecessary prompts but shouldn’t be sole high-assurance factor.
Conclusion
Behavioral biometrics is a powerful, privacy-sensitive approach to continuous authentication and fraud detection that integrates across edge, cloud, and ops layers. Its success depends on strong data hygiene, observability, careful SLO design, and cross-functional ownership. Short-term investments in instrumentation, labeling, and safe model deployment practices pay off in reduced fraud and better user experience.
Next 7 days plan (practical):
- Day 1: Audit available telemetry and legal/privacy requirements.
- Day 2: Implement minimal client SDK event schema and consent UI in staging.
- Day 3: Stand up streaming ingestion and basic feature store.
- Day 4: Deploy a simple scoring microservice and instrument SLIs.
- Day 5: Run load and latency tests; set SLOs and alerts.
- Day 6: Execute an initial canary with 1% traffic and monitor.
- Day 7: Review results, collect labels, and plan next iteration.
Appendix — Behavioral Biometrics Keyword Cluster (SEO)
- Primary keywords
- behavioral biometrics
- continuous authentication
- behavioral authentication
- keystroke dynamics
- mouse movement biometrics
- touch gesture biometrics
- behavioral risk scoring
- adaptive authentication
-
behavioral biometrics 2026
-
Secondary keywords
- behavioral biometrics architecture
- behavioral biometrics cloud
- edge inference biometrics
- federated learning biometrics
- privacy-preserving biometrics
- behavioral template management
- feature store for biometrics
- model serving biometrics
- biometrics observability
-
biometrics SLI SLO
-
Long-tail questions
- what is behavioral biometrics and how does it work
- how to implement behavioral biometrics in kubernetes
- serverless behavioral biometrics architecture
- how to measure behavioral biometrics performance
- behavioral biometrics privacy concerns and compliance
- best tools for behavioral biometrics monitoring
- how to reduce false positives in behavioral biometrics
- continuous authentication using behavioral biometrics
- edge vs cloud scoring for behavioral biometrics
- how to handle model drift in behavioral biometrics
- how to collect keystroke dynamics safely
- can behavioral biometrics prevent account takeover
- difference between device fingerprinting and behavioral biometrics
- how to scale behavioral biometrics pipelines
-
implementing consent for behavioral telemetry
-
Related terminology
- anomaly detection
- model drift
- feature engineering
- differential privacy
- federated learning
- canary deployment
- model registry
- feature store
- streaming ETL
- ATO prevention
- fraud detection
- IAM integration
- SIEM correlation
- user sessionization
- liveness detection
- ensemble models
- calibration
- label pipeline
- cost per million scores
- telemetry enrichment



Leave a Reply
You must be logged in to post a comment.