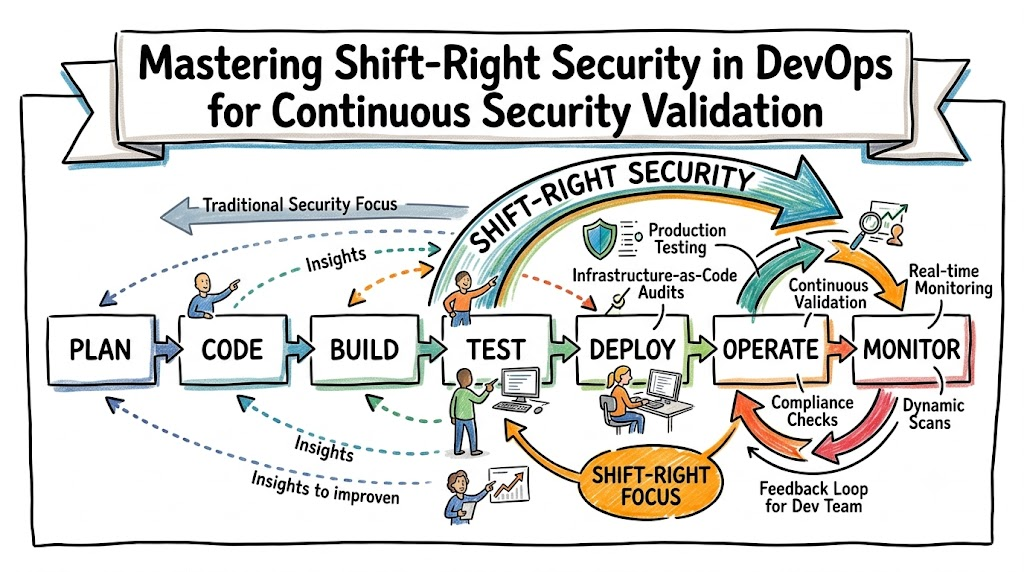
Introduction
In modern software engineering, the journey of an application does not end when code passes a continuous integration pipeline and successfully deploys to a Kubernetes cluster or a cloud environment. For many years, the technology industry focused heavily on moving security tests earlier in the development lifecycle, a concept known as shifting left. While catching vulnerabilities during coding, static analysis, and container scanning is critical, it only solves one half of the security equation.
Cloud-native applications are highly dynamic, built on distributed microservices architectures, and run inside infrastructure that changes constantly. Vulnerabilities can emerge after deployment due to misconfigurations, newly discovered zero-day exploits, or compromised credentials. No matter how thorough your pre-deployment testing is, you cannot test software against live production traffic, unpredictable user behavior, or advanced persistent threats before it goes live. This is where Shift-Right Security in DevOps becomes an absolute necessity for organizations striving to maintain secure systems.
Production monitoring, continuous logging, and real-time observability form the defensive shield of modern deployments. Without visibility into running systems, an organization remains blind to active exploits, memory injections, or unauthorized data exfiltration. By focusing on runtime protection, engineering teams ensure that security validation remains an active, ongoing process that protects applications during their entire lifecycle. To master these essential production security methodologies, professionals frequently utilize structured training resources such as the comprehensive DevSecOps and cloud security programs offered by DevOpsSchool.
Consider a real-world scenario: an engineering team uses top-tier static analysis tools to verify their application code before deployment. The application passes all checks and goes live. Three weeks later, a critical vulnerability is discovered in an underlying open-source logging library utilized by the application. Because the code is already running in production, pre-deployment scans cannot prevent an attacker from attempting to exploit this live flaw. Only a dedicated runtime security strategy can detect the abnormal system behavior, alert the operations team, and block the malicious traffic before a major data breach occurs.
What Is Shift-Right Security in DevOps?
Shift-Right Security in DevOps refers to the practice of implementing security testing, continuous monitoring, guardrails, and real-time threat detection during the post-deployment phase of the software development lifecycle. While traditional security models focus on securing code during the planning, building, and testing phases, the shift-right philosophy extends security practices directly into live production environments where applications interact with real users, live databases, and public networks.
[ Code ] ──> [ Build ] ──> [ Test ] ──> [ Deploy ] ──> [ Production Run ]
│ │ │
└─────────── SHIFT-LEFT ─────────────────┘ └────── SHIFT-RIGHT ──────┘
(Static Scans, Unit Tests, Commit Checks) (Runtime Monitoring, SIEM)
In a traditional deployment model, security was often treated as a gatekeeping mechanism handled by an isolated security team right before software went live. In modern DevOps, security must operate as a continuous loop. Shifting right means focusing heavily on runtime monitoring, active system observability, log analysis, configuration drift detection, and automated incident response. It acknowledges that software is inherently subject to change and that production is the ultimate testing ground for security resilience.
To understand this in a beginner-friendly way, think of securing a high-security building. Shifting left is comparable to screening the blueprints of the building, checking the backgrounds of the construction workers, and inspecting the quality of the building materials before anyone moves in. Shifting right is comparable to installing security cameras, motion sensors, security guards, and alarm systems once the building is occupied and open to the public. Both strategies are necessary; screening building materials cannot stop an unauthorized intruder from slipping through an open front door on a Tuesday afternoon.
When applied to software systems, Shift-Right Security in DevOps ensures that when a microservice behaves unexpectedly—such as trying to open an unapproved outbound network connection or attempting to read restricted system files—the system identifies the anomaly instantly. It bridges the gap between development-centric security scans and live operations, ensuring that protection remains continuous.
Why Traditional Security Is No Longer Enough
The rapid evolution of cloud infrastructure, containerization, and microservices has rendered traditional static security models insufficient. In legacy environments, software was updated quarterly or annually, running on predictable, long-lived physical servers. Security teams could perform manual penetration tests, review architecture diagrams, and sign off on releases with a high degree of confidence that the runtime environment would remain unchanged for months.
Today, modern cloud-native environments are highly dynamic. Infrastructure as Code (IaC) allows developers to spin up or tear down thousands of cloud resources in minutes. Containers run for hours or even minutes before being replaced. In this state of constant flux, static security checks performed during the build phase become outdated almost the moment the software is deployed.
Traditional Security: Fixed Infrastructure ──> Scheduled Audits ──> High Visibility
Modern Infrastructure: Dynamic Containers ──> Continuous Changes ──> High Complexity
Production environments face a multitude of risks that cannot be simulated or evaluated during the compilation of source code:
- Configuration Drift: Cloud resources might be deployed securely, but subsequent automated updates or manual emergency changes can introduce misconfigurations, such as leaving an Amazon S3 bucket open to the public or exposing an internal database port to the internet.
- Zero-Day Exploits: Vulnerabilities within trusted third-party libraries can be discovered at any moment. If an exploit is announced after your software has been running in production for six months, pre-deployment tools provide zero protection against hackers targeting that live vulnerability.
- Insiders and Credential Theft: If an attacker compromises legitimate administrative credentials through a phishing campaign, pre-deployment static analysis will not flag any issues. The attacker is using valid credentials to access production systems, which can only be detected by monitoring runtime behavioral anomalies.
- Dynamic API Attacks: Modern applications rely heavily on APIs to communicate. Malicious actors frequently probe live endpoints with unconventional payloads to exploit logical flaws in business logic, bypass authentication mechanisms, or execute unauthorized database queries that static scanners cannot predict.
Consider a practical scenario involving a global containerized application. The CI/CD pipeline scans every container image for known security flaws, and the build receives a clean bill of health. Once deployed to a live Kubernetes cluster, an administrator accidentally updates an network policy during a troubleshooting session, inadvertently exposing an internal caching server to the public internet.
Traditional pre-deployment security scanning cannot detect this infrastructure modification because it occurred directly within the live environment long after the deployment pipeline concluded. Without shift-right security practices in place, this open database could remain exposed for weeks, allowing malicious actors to harvest customer session data completely unnoticed by the development team.
Shift-Left vs Shift-Right Security
To build a comprehensive security posture, organizations must understand how shift-left and shift-right security methodologies complement each other. They are not competing ideologies; rather, they are two halves of a continuous engineering feedback loop.
| Factor | Shift-Left Security | Shift-Right Security |
| Timing | Executed during planning, coding, building, and pre-production testing phases. | Executed during deployment, post-deployment, runtime, and operations phases. |
| Primary Purpose | Prevent vulnerabilities, coding errors, and known bugs from entering production. | Detect live attacks, zero-day exploits, system anomalies, and configuration drifts. |
| Focus Area | Source code, dependencies, container images, and static infrastructure templates. | Running containers, live cloud infrastructure, production logs, and active network traffic. |
| Core Examples | SAST, DAST, SCA dependency scanning, and pre-commit linting tools. | Runtime threat detection, SIEM log analysis, synthetic testing, and cloud monitoring. |
| Key Benefits | Lowers the cost of fixing bugs early; ensures developers follow secure coding standards. | Provides absolute production visibility; enables rapid incident response and runtime resilience. |
To illustrate the difference using a practical example, let us look at how an e-commerce platform handles customer payment processing:
During the Shift-Left Phase, developers use Static Application Security Testing (SAST) to ensure that the payment processing code does not accidentally log credit card numbers to standard output. They also run Software Composition Analysis (SCA) to verify that third-party encryption libraries contain no known security flaws.
During the Shift-Right Phase, once the payment application is running live and handling thousands of real customer transactions, security tools monitor the actual behavior of the payment container. If the container suddenly attempts to establish an outbound SSH connection to an unknown IP address in a foreign country, shift-right systems immediately flag this runtime anomaly, block the network traffic, and alert the on-call incident response team.
Why Shift-Right Security Matters in DevOps
Implementing Shift-Right Security in DevOps is critical because production environments are the ultimate destination where business value is delivered and where real-world threats operate. Relying solely on pre-deployment checks creates a false sense of security, leaving organizations vulnerable to post-deployment operational realities.
Production Visibility ──> Anomaly Detection ──> Real User Insights ──> Rapid Mitigation
Absolute Production Visibility
Production systems are complex webs of interacting services, third-party APIs, database connections, and cloud infrastructure components. Shift-right practices provide engineers with an accurate view of how these systems behave under heavy load, real user interactions, and unexpected edge cases. This visibility ensures that security teams can audit the true state of their production environment at any given second.
Accurate Threat Detection
While pre-deployment testing looks for hypothetical vulnerabilities, shift-right security looks for active, real-world exploitation attempts. It identifies SQL injection strings hitting live database endpoints, brute-force login attempts, cross-site scripting payloads executed in real user browsers, and lateral movement attempts across microservices inside an internal network.
Real User Behavior Monitoring
Security risks do not always stem from broken code; they can originate from malicious user behavior. Shift-right security tracks how users interact with applications. If an account suddenly attempts to download thousands of invoices within a single minute, shift-right mechanisms spot this behavioral divergence from standard human patterns and apply rate-limiting or account suspension protocols.
Faster Incident Response
When a security incident occurs, every second matters. Shift-right security systems provide real-time alerting mechanisms linked directly to automated remediation workflows. Instead of waiting for a quarterly audit or an external bug bounty report to discover an intrusion, engineering teams receive immediate, actionable alerts that allow them to contain breaches before they escalate into catastrophic data losses.
Consider a corporate workplace scenario: a financial technology firm experiences an unexpected security incident where an administrative credential is leaked on a public developer forum. The attacker uses this valid credential to log into the cloud management console and begins altering user access permissions. Because the attacker uses legitimate authentication credentials, pre-deployment pipelines and standard code repositories show no signs of compromise.
However, because the firm implemented a robust shift-right security strategy, an automated cloud configuration monitoring tool immediately flags the anomalous administrative logins coming from an unrecognized geographic region at 2:00 AM. The system instantly revokes the compromised credential, rolls back the unauthorized permission changes, and pages the security operations center, mitigating a potentially devastating data breach within minutes.
Core Components of Shift-Right Security
A successful shift-right security model is built upon several foundational components that collectively provide continuous security validation across the production infrastructure.
| Component | Core Purpose |
| Runtime Monitoring | Tracks the active execution of processes, system calls, and file system modifications on live servers. |
| Security Observability | Consolidates metrics, logs, and distributed traces to provide deep contextual insights into system health. |
| Incident Detection | Evaluates real-time events against known threat intelligence signatures and behavioral baselines. |
| Log Analysis | Aggregates, parses, and retains historical record data from across all applications and infrastructure layers. |
| Threat Intelligence | Integrates external databases of known malicious IP addresses, domains, and malware signatures. |
| Chaos Engineering | Injecting controlled failures and security anomalies into production to validate defensive systems. |
To understand how these components work together, let us analyze a production workflow:
[ Live System Activity ] ──> [ Log Analysis & Observability ] ──> [ Threat Engine Evaluation ]
│
[ Remediation & Alerting ] <── [ Incident Detection & Routing ] <───────┘
- Live Activity Generation: Applications, databases, and network gateways generate continuous streams of system calls, network packets, and operational logs.
- Aggregation & Observability: Tools collect these streams, indexing metrics and raw logs into centralized data stores for real-time indexing.
- Threat Evaluation: Automated evaluation engines compare this operational data against behavioral baselines and global threat databases to identify indicators of compromise.
- Incident Routing: If a risk profile is exceeded, an incident detection system generates an alert, routes it to the appropriate on-call engineering team, or triggers automated remediation tasks to neutralize the risk.
Area #1: Runtime Security Monitoring
Runtime security monitoring focuses on inspecting the actual execution of software inside its production environment. This involves observing system calls, process state transitions, file system activities, and network socket creations at the operating system kernel level.
[ Application Process ] ──> [ System Call ] ──> [ OS Kernel Linux (eBPF / Falco) ] ──> [ Alert Triggered ]
In containerized cloud environments running on platforms like Kubernetes, runtime security often leverages modern technologies like Extended Berkeley Packet Filter (eBPF). eBPF allows security tools to run safely inside the Linux kernel, monitoring system events with negligible performance overhead. This means security tools can witness exactly what an application process is doing in real-time.
A primary open-source standard for runtime security in container environments is Falco. Falco acts as a security camera for running applications. It monitors system calls against a customizable rule engine. If a container behaves in a manner that violates its expected execution profile, Falco generates a detailed security alert.
YAML
# Simplified example of a Falco runtime security rule
- rule: Unauthorized Shell in Container
desc: Detect lookups where a user or script spawns a shell inside a running container
condition: container.id != host and proc.name = bash
output: "Alert: Malicious shell spawned inside container (user=%user.name container=%container.id cmd=%proc.cmdline)"
priority: CRITICAL
Consider a production example: a microservice running an API endpoint is compromised via a remote code execution vulnerability. The attacker leverages the exploit to force the application process to spawn a bash shell inside the running container and attempts to run apt-get update to install network scanning tools.
Because the container was built to only run a compiled binary, spawning a shell is a highly irregular behavior. A runtime monitoring tool detects this system call immediately, notes that bash was initiated by an unauthorized process, kills the compromised container instance, and sends an urgent alert to the platform security team.
Area #2: Security Observability
Security observability extends traditional infrastructure monitoring by combining data streams to help engineers understand why a system is behaving a certain way, rather than just that it is failing. Traditional monitoring tells you that system memory usage is at 98%; security observability helps you determine if that memory spike is caused by a surge in customer traffic or a malicious actor executing a denial-of-service attack.
Observability Triad = [ Detailed Metrics ] + [ Centralized Logs ] + [ Distributed Traces ]
The foundations of security observability rely on three distinct data types:
- Metrics: Numeric values measured over intervals of time (e.g., HTTP request counts, database error rates, CPU consumption patterns).
- Logs: Text-based records of specific events that occurred at a precise timestamp (e.g., audit logs, authentication failures, application exceptions).
- Traces: End-to-end paths of a single request as it travels across multiple distributed microservices, databases, and third-party APIs.
In modern engineering, tools like Prometheus and Grafana are widely used to build observability pipelines. Prometheus scrapes and stores time-series performance metrics from applications and infrastructure layers. Grafana connects to Prometheus and log aggregation engines to visualize this data through comprehensive, real-time dashboards.
For instance, a security engineer can build a Grafana dashboard that visualizes the ratio of successful user logins to failed user logins across the entire platform.
If an attacker launches a distributed credential stuffing attack against the user authentication service, the Prometheus metrics will show an immediate, sharp spike in HTTP 401 (Unauthorized) error codes. By overlaying this metric with distributed tracing data, engineers can isolate exactly which microservices are processing the malicious traffic and apply global IP rate limits to stop the attack.
Area #3: Incident Detection and Response
Incident detection and response within a shift-right security model ensures that when a security anomaly is identified, the organization can contain and remediate the risk immediately. This prevents minor security alerts from developing into widespread system compromises.
Central to this area are Security Information and Event Management (SIEM) systems and Security Orchestration, Automation, and Response (SOAR) workflows. A SIEM acts as a centralized brain, collecting data from cloud infrastructure, firewalls, identity providers, and application logs. It correlates seemingly unrelated events to detect sophisticated attacks.
[ Multiple Event Sources ] ──> [ SIEM Aggregation Engine ] ──> [ Correlation Rules ] ──> [ Automated Playbook Response ]
A realistic production response workflow operates as follows:
[ Malicious Brute Force Detected ]
│
▼
[ SIEM Correlates Multiple Failed Logins ]
│
▼
[ SOAR Triggered: Block Attacker IP in Firewall ]
│
▼
[ Notify On-Call Team via PagerDuty / Slack ]
- Correlation: A SIEM notices that a single IP address has failed to log into ten different user accounts within thirty seconds, while simultaneously scanning internal network ports.
- Orchestration: The SIEM triggers an automated SOAR playbook designed for brute-force mitigation.
- Automated Enforcement: The automated playbook communicates directly with cloud firewalls or content delivery networks (CDNs) to dynamically block the attacker’s IP address.
- Notification: The system logs the incident, closes the vulnerable vector, and notifies the on-call security engineer via communications channels like PagerDuty or Slack with a detailed summary of the actions taken.
This automated response ensures that systems are protected 24/7 without requiring manual human intervention for every common threat pattern, dramatically reducing the mean time to remediate (MTTR) active production exploits.
Area #4: Production Log Analysis
Production log analysis is the practice of collecting, parsing, and reviewing historical event logs to investigate system anomalies, debug application errors, and conduct post-incident forensic investigations. Logs are the immutable truth of what transpired inside an application environment.
[ Application Logs ] + [ Cloud Audit Logs ] + [ OS Access Logs ] ──> [ Log Parser ] ──> [ Centralized Search Index ]
Without a centralized log analysis strategy, engineers are forced to manually log into individual servers or containers to check local log files via command-line utilities. In modern architecture, where containers are ephemeral and vanish when restarted, local logs are lost forever. Shift-right practices require streaming all logs immediately to an external, centralized log management platform.
Consider a practical security troubleshooting example: an engineering team notices a strange sequence of database read errors occurring every day at midnight. A security engineer performs an investigation using centralized log analytics by running a structured query across application access logs and database audit logs.
SQL
-- Conceptual search pattern for investigating unauthorized query patterns
SELECT timestamp, client_ip, request_uri, status_code
FROM application_access_logs
WHERE request_uri LIKE '%UNION SELECT%'
ORDER BY timestamp DESC;
The query reveals that a specific client IP address has been sending malicious payloads containing SQL injection commands hidden inside the HTTP user-agent header field. The database read errors were caused by the database rejecting these malformed malicious queries.
Armed with this log data, the engineering team can patch the vulnerable input field, submit the attacker’s IP address to a global blocklist, and confirm via database transaction logs that no actual customer records were leaked during the probing window.
Area #5: Continuous Security Validation
Continuous security validation is the active practice of testing a running production system’s defenses to ensure that security configurations, monitoring tools, and alerting structures work as intended. This is where security teams move from passive monitoring to active testing.
A major methodology within continuous validation is Chaos Engineering for Security (often called Security Chaos Engineering). Historically, chaos engineering focused on reliability—such as intentionally shutting down a server to see if the system automatically redirects traffic to a healthy backup server. Security chaos engineering applies this same philosophy to security controls.
[ Inject Controlled Security Failure ] ──> [ Observe Detection Pipelines ] ──> [ Verify Alerts & Guardrails ]
Instead of waiting for an actual hacker to test if your alerts work, security teams intentionally inject a controlled security failure into the production environment. For example, a scheduled automated script might attempt to download a simulated malware file onto a production host or try to modify a restricted cloud configuration setting.
The objective is to verify if the detection systems function correctly:
- Did the runtime monitoring tool catch the unauthorized behavior?
- Did the logging system record the event accurately?
- Did the alerting system page the on-call engineer within the required time window?
- Did the automated guardrails block the activity before it caused harm?
If the team discovers that the simulated attack went completely unnoticed, they know they have a critical visibility gap. They can adjust their monitoring rules and configuration alerts immediately, ensuring that if a real threat actor attempts the same tactic in the future, the organization’s defenses will respond instantly.
Real-World Scenario: Team Without Shift-Right Security
To appreciate the practical impact of these methodologies, let us evaluate the operational experience of an organization that relies exclusively on pre-deployment shift-left security testing, completely neglecting shift-right visibility.
The Context
An enterprise software team builds an online banking component. They execute comprehensive SAST scans, run daily container image checks, pass all vulnerability assessments, and successfully deploy their software to production. They assume their system is perfectly secure because the deployment pipeline showed zero errors.
The Incident Workflow
[ Week 1: Zero-Day Exploit Released ] ──> [ Week 2: Attacker Compromises Server ] ──> [ Week 4: Ransomware Encrypts Data ]
│
[ Complete System Downtime ] <── [ Customer Inquiries Flood In ] <── [ Week 8: Public Disclosure ] ◄──┘
- Day 01: An advanced zero-day vulnerability is publicly disclosed in a popular open-source utility framework used by the banking component. The team’s running production servers are now vulnerable, but because no new code is being deployed, the CI/CD pipeline does not run, leaving the team unaware of the exposure.
- Day 15: A malicious actor scans the public internet, identifies the bank’s exposed live application endpoint, and executes the zero-day exploit. The attacker gains remote access to an active production container.
- Day 16 to Day 30: Because the team has no runtime monitoring tools or centralized log analysis in production, the attacker moves laterally across the internal network. The actor quietly reads sensitive database configuration files, downloads customer account details, and installs backdoors.
- Day 45: The attacker deploys a ransomware script that encrypts the primary transaction database, rendering the bank’s services completely non-operational.
- Day 46: The engineering team awakens to massive system outages and thousands of customer complaints. Because local container logs were deleted by the attacker, the team has no forensic evidence to determine how the breach occurred, how long the hacker was inside, or what specific data was stolen.
The lack of shift-right visibility turned a patchable zero-day vulnerability into a catastrophic business failure, resulting in extensive financial remediation costs, severe brand degradation, and strict regulatory penalties.
Real-World Scenario: Team Using Shift-Right Security
Now, let us examine the exact same scenario, but with an engineering team that has fully integrated Shift-Right Security in DevOps into their operational workflows.
The Context
The same banking application is deployed. The engineering team utilizes identical shift-left pre-deployment scans, but they also deploy runtime monitoring agents, centralized log dashboards, and automated alert routes across their live cloud infrastructure.
The Incident Workflow
[ Day 01: Zero-Day Released ] ──> [ Day 15: Attacker Initiates Exploit ] ──> [ Runtime Detection (Falco) Triggers ]
│
[ Post-Mortem & Patching ] <── [ Attacker Blocked & Isolated ] <── [ Automated Incident Playbook Executes ] ◄┘
- Day 01: The zero-day vulnerability is announced. While the development team schedules a sprint task to update the library code, the production environment remains actively protected by behavioral runtime guardrails.
- Day 15 (02:10 AM): An attacker attempts to exploit the zero-day flaw on the live production endpoint, attempting to force the application container to execute an unauthorized binary downloadd script.
- Day 15 (02:10 AM + 4 Seconds): The runtime monitoring tool (such as Falco) intercepts the unauthorized system call instantly. It identifies that an application process is attempting to access external public storage networks to download an unapproved file.
- Day 15 (02:10 AM + 12 Seconds): The runtime engine automatically triggers an incident response playbook. The compromised container instance is isolated from the network and terminated, and a fresh, clean container instance is spun up automatically to preserve system availability for real users.
- Day 15 (02:11 AM): The automated system updates the perimeter firewall rules to block the attacker’s IP address entirely. Simultaneously, a high-priority alert containing full process traces and contextual log streams is sent to the on-call engineer’s mobile device.
- Day 15 (09:00 AM): The engineering team reviews the centralized log analysis dashboards to confirm that the attack was successfully blocked. They verify that no data was exfiltrated, complete a standard post-mortem, and roll out the permanent framework patch to production via the CI/CD pipeline.
By prioritizing shift-right practices, the organization minimized a severe security threat into a non-disruptive event, ensuring continuous application availability and total data protection.
Common Misconceptions About Shift-Right Security
As organizations transition to a modern DevSecOps model, several misconceptions often arise regarding what shift-right security entails and how it should be implemented.
- Misconception #1: Shift-Right Replaces Shift-Left Security
- The Reality: Shift-right security does not replace shift-left testing. They are symbiotic practices. Shift-left eliminates the vast majority of known code defects and vulnerabilities before they ever leave a developer’s machine, keeping the production environment clean. Shift-right manages the unpredictable operational realities that shift-left cannot see. You need both to achieve comprehensive security.
- Misconception #2: Security Ends Once Monitoring Tools Are Installed
- The Reality: Installing an agent or activating a monitoring platform is merely the initial step. Security is an active process of tuning rules, reducing false positives, analyzing metrics, and developing incident response playbooks. A monitoring tool that generates thousands of unreviewed alerts provides no actual security.
- Misconception #3: Basic Performance Monitoring Equals Security Observability
- The Reality: Standard application performance monitoring (APM) tools track availability and speed, such as page load times and server uptime. Security observability requires tracking security-specific indicators, such as authentication anomalies, user access permissions changes, cryptographic operations, and unexpected system kernel calls.
- Misconception #4: Runtime Security Is Exclusively for Large Scale Enterprises
- The Reality: Small businesses and startups are frequent targets for automated cyberattacks. Thanks to modern open-source projects like Falco, Prometheus, and centralized logging frameworks, runtime security and shift-right observability can be implemented by teams of any size with minimal financial expenditure.
Benefits of Shift-Right Security
Integrating Shift-Right Security in DevOps yields profound operational advantages that directly enhance an organization’s security posture and system reliability.
┌───> Rapid Detection (Seconds vs Months)
├───> Operational Resilience (Auto-Healing)
Shift-Right ──────┼───> Data-Driven Decisions (Forensic Evidence)
└───> Complete Cloud Visibility (Drift Identification)
Rapid Detection of Live Infiltrations
Instead of relying on historical forensic audits or discovering a breach months after it occurred via a third-party notification, shift-right security shrinks detection windows down to seconds. This rapid identification prevents attackers from establishing a permanent foothold inside internal corporate networks.
Enhanced Operational Resilience
By coupling runtime monitoring with automated containment protocols, applications gain self-healing capabilities. When a microservice undergoes an exploit attempt, the infrastructure can isolate the affected component, block the malicious traffic source, and maintain uninterrupted service delivery for legitimate global customers.
Contextual Data for Root-Cause Engineering
When code failures or security events happen in production, shift-right observability pipelines capture the exact state of the system, including exact application memory utilization, distributed traces, and log entries. This extensive data allows developers to reproduce the underlying issue accurately and deploy permanent code patches quickly without guesswork.
Validation of True Infrastructure State
Shift-right tools continuously scan running infrastructure configurations against organizational baselines. This ensures that accidental changes made during late-night debugging sessions or dynamic infrastructure adjustments do not create permanent gaps in the external security perimeter.
Challenges in Shift-Right Security Adoption
While the advantages of shift-right practices are substantial, engineering leadership must acknowledge and navigate several common operational hurdles during adoption.
Management of Alert Fatigue
Production environments generate vast quantities of daily log and metric data. If monitoring thresholds and correlation rules are configured too aggressively, security platforms will inundate engineering teams with hundreds of low-priority or false-positive alerts. Over time, this causes alert fatigue, leading engineers to ignore notifications or mute channels, which can result in missing a real attack.
Technical Complexity and Performance Overhead
Deploying monitoring agents, log forwarders, and kernel-level tracing utilities across thousands of distributed cloud containers requires careful architectural planning. If improperly configured, these security tools can consume excessive CPU and memory resources, increasing cloud infrastructure costs and introducing latency into customer application workflows.
The DevSecOps Skills Shortage
Operating a successful shift-right paradigm requires professionals who understand software development pipelines, system engineering, cloud infrastructure, and core security methodologies simultaneously. Finding and training engineers capable of navigating log query languages, cloud firewall rules, and container runtime architectures represents a significant hurdle for many global organizations.
Cross-Team Operational Silos
Historically, development teams, operations teams, and dedicated security units functioned inside strictly segregated organizational silos. Shift-right security requires tight collaboration. If developers view production alerts as an exclusive “operations problem,” or if security teams build monitoring configurations without understanding application architecture, the implementation will fail to protect the enterprise effectively.
Best Practices for Implementing Shift-Right Security
To successfully integrate Shift-Right Security in DevOps without disrupting development velocity, organizations should adopt a structured, iterative implementation strategy.
1. Build a Unified Feedback Loop
Ensure that insights discovered in production by shift-right tools are fed directly back into the shift-left phase. If runtime logs show that an application is frequently targeted by a specific class of API authorization probing, the security team must update pre-deployment static analysis rules and developer training standards to address that specific architectural pattern early in the next code cycle.
2. Implement Progressive Alert Tuning
When introducing runtime monitoring tools like Falco or SIEM platforms, initiate deployments with alerts set to log-only mode. Observe the volume of generated events across a two-week baseline period, isolate false positives caused by standard application activity, tune the rule parameters accordingly, and only activate live on-call paging for high-confidence, critical security anomalies.
3. Automate Containment Rather Than Full Remediation
When designing automated response playbooks, prioritize low-risk containment strategies first. For instance, instructing an automated script to instantly isolate a suspicious container or apply temporary rate-limiting to an IP address is safe and preserves data integrity. Avoid designing complex automated scripts that delete database volumes or alter core codebase states automatically, as minor monitor glitches could cause unintended self-inflicted system downtime.
4. Maintain a Production Security Checklist
Ensure your engineering teams track production deployment health against an established operational checklist:
- [ ] Verify centralized log forwarding agents are active and streaming on all live production nodes.
- [ ] Confirm runtime security monitoring rules (e.g., Falco rules) are updated to match the application’s process profile.
- [ ] Audit cloud infrastructure resources to ensure zero configuration drift from baseline Infrastructure as Code templates.
- [ ] Validate that metric collection dashboards (e.g., Prometheus/Grafana) have clear thresholds set for unexpected traffic spikes.
- [ ] Conduct regular, controlled security chaos engineering simulations to confirm that incident response paths function within SLA guidelines.
Role of DevOpsSchool in Learning DevSecOps
Navigating the multi-faceted landscape of modern application protection requires deep practical knowledge across multiple engineering domains. Aspiring specialists, system administrators, and seasoned software developers frequently look for structured educational ecosystems to accelerate their mastery of these complex real-world technologies. This is where educational platforms like DevOpsSchool play an invaluable role in the technology sector.
DevOpsSchool provides comprehensive, industry-aligned training programs designed to demystify complex cloud-native methodologies. Rather than focusing solely on theoretical software concepts, their educational curriculum emphasizes hands-on exposure to the foundational tools that drive shift-left and shift-right security frameworks.
Through structured, mentor-led bootcamps and specialized DevSecOps courses, learners gain direct experience in configuring production-grade environments:
- Runtime Security Implementations: Setting up open-source container monitoring platforms like Falco to intercept and evaluate real-time system calls inside live Kubernetes environments.
- Production Observability Foundations: Building metric-gathering architectures with Prometheus and designing comprehensive visual security dashboards inside Grafana to trace system behavior under simulated stress.
- Advanced Log Analytics: Developing centralized logging pipelines that aggregate, index, and analyze text-based event records from disparate microservices to perform root-cause forensic investigations.
- Automated Incident Engineering: Designing resilient workflows that link infrastructure alerts directly to automated containment playbooks, ensuring immediate response capabilities.
By focusing on real-world production scenarios and cloud-native practices, such educational frameworks empower engineers to bridge the gap between development velocity and production stability, helping modern organizations build reliable and inherently secure software delivery systems.
Career Importance of Shift-Right Security Skills
As enterprises globally migrate their core operations to cloud infrastructure, the demand for engineering professionals who possess deep runtime security and observability expertise has reached an all-time high. Understanding how to write code is no longer sufficient; the modern technology market rewards those who know how to protect code when it runs at scale.
Mastering Shift-Right Security opens up diverse career advancement paths across multiple core engineering specialties:
DevSecOps Engineer
Professionals in this role act as the primary bridge between development pipelines and corporate security policies. They specialize in embedding security scanners into CI/CD workflows while simultaneously deploying runtime detection engines across production clusters to maintain a continuous security lifecycle.
Site Reliability Engineer (SRE)
SREs focus on system availability, performance latency, and operational efficiency. By mastering security observability, an SRE ensures that production infrastructure remains highly resilient against both unexpected software infrastructure failures and malicious external denial-of-service attacks.
Cloud Security Architect
Architects design the overarching structural blueprints for an organization’s global cloud footprint. They leverage shift-right methodologies to establish immutable logging perimeters, design automated configuration drift enforcement guardrails, and structure multi-tenant access models.
Platform Engineer
Platform specialists build the internal developer portals and underlying infrastructure systems that product development teams utilize daily. Integrating runtime monitoring agents and automated security guardrails directly into the base platform ensures that every application deployed by developers is automatically protected by default from day one.
To excel in these high-value career paths, professionals must actively cultivate a balanced technical skill set:
┌───> Systems: Linux Kernel, System Calls, eBPF
├───> Tools: Falco, Prometheus, Grafana, ELK/PLG Stack
Required Skills ──┼───> Automation: Shell Scripting, Python, SOAR Playbooks
└───> Architecture: Kubernetes, Cloud Guardrails, Microservices
By transitioning from a purely pre-deployment testing mindset to an advanced operational engineering posture, technology professionals position themselves as invaluable assets capable of safeguarding critical corporate data assets in a complex, unpredictable global threat environment.
Industries Using Shift-Right Security
The adoption of Shift-Right Security in DevOps spans across every global industry sector that relies on cloud software to deliver business value. Wherever sensitive user transactions and valuable data assets exist, runtime protection is mandatory.
┌────────────────────────────────────────────────────────────────────────┐
│ INDUSTRIES LEVERAGING SHIFT-RIGHT │
├──────────────┬──────────────┬───────────────┬─────────────┬────────────┤
│ Banking │ Healthcare │ SaaS Platforms│ E-Commerce │ Telecom & │
│ & Finance │ & Medical │ & B2B Tech │ & Retail │ Enterprise │
└──────────────┴──────────────┴───────────────┴─────────────┴────────────┘
Banking, FinTech, and Financial Services
Financial platforms handle thousands of high-value digital transactions every second. They are primary targets for highly sophisticated threat actors seeking to commit fraud or steal capital. Financial institutions utilize shift-right security to track transactional behavioral patterns, monitor database access lines, and instantly isolate unauthorized attempts to modify account balance records in production.
Healthcare and Medical Technology
Healthcare applications store highly confidential patient data protected by strict global privacy regulations (such as HIPAA). Because medical systems must remain continuously available to preserve patient well-being, shutting down an entire application during a suspected security incident is not an option. Shift-right practices allow healthcare security teams to isolate single compromised microservices quietly while ensuring doctors and nursing staff maintain continuous, uninterrupted access to critical patient health records.
Enterprise SaaS and Cloud Platforms
Business-to-business software-as-a-service providers host proprietary data for hundreds of corporate clients on shared cloud infrastructure. A data breach affecting a single tenant could propagate across multiple clients, resulting in catastrophic legal and financial liabilities. SaaS engineering teams leverage runtime security monitoring to enforce strict multi-tenant boundary isolation, ensuring no container can access memory addresses or network sockets belonging to a different client.
Digital E-Commerce and Global Retail
Retail platforms face massive, volatile swings in user traffic during seasonal holiday shopping events. These high-volume periods are frequently weaponized by malicious actors launching credential stuffing attacks or automated bots designed to scrape inventory data. Shift-right observability metrics allow e-commerce platforms to differentiate human checkout behavior from automated malicious scripts, maintaining application speed and availability for legitimate global consumers.
Future of Shift-Right Security
As cloud ecosystems continue to mature, the methodologies driving Shift-Right Security in DevOps are undergoing a significant technological transformation, moving from manual intervention models toward intelligent, autonomous operations.
Manual Audits ──> Rule-Based Alerting ──> AI Threat Analysis ──> Autonomous Self-Healing Systems
AI-Assisted Threat Detection and Noise Reduction
The integration of specialized artificial intelligence and machine learning models into SIEM and log aggregation platforms is revolutionizing how organizations handle production telemetry. Instead of relying exclusively on static, human-written alert rules, AI analysis engines evaluate massive streams of infrastructure metrics in real-time to identify micro-anomalies that escape human observation, while simultaneously filtering out thousands of false-positive events to completely eliminate alert fatigue.
Complete Cloud-Native Security Evolution via eBPF
The widespread adoption of Extended Berkeley Packet Filter (eBPF) technology is transforming runtime visibility. Future security tools will operate entirely within the operating system kernel layer, providing deep, low-overhead observability into application behavior without requiring invasive code modifications or heavy sidecar container architectures. This makes runtime security a frictionless, native component of cloud operating systems.
Shift-Left and Shift-Right Convergence
The artificial boundary separating development-phase security and operations-phase security is dissolving. Future DevSecOps platforms will provide unified control consoles where pre-deployment code scanning data is directly correlated with live production behavioral insights. If a vulnerability is detected in code but cannot be patched immediately, the system will automatically configure and deploy a corresponding runtime guardrail in production to block attempts to exploit that specific vulnerability, creating an intelligent, closed-loop defensive ecosystem.
FAQs (Frequently Asked Questions)
What is Shift-Right Security?
Shift-Right Security is the practice of implementing security monitoring, testing, vulnerability validation, and incident threat response directly inside live production environments after an application has been deployed. It ensures continuous security throughout the operational lifecycle of software.
Is Shift-Right Security better than Shift-Left Security?
Neither is superior; they are both essential components of a complete security strategy. Shift-left security aims to prevent vulnerabilities during the coding and build phases. Shift-right security detects active exploits, misconfigurations, and zero-day vulnerabilities during live execution. They work together to provide comprehensive application protection.
Why do we need security monitoring in production if our code passed all CI/CD scans?
Pre-deployment scans can only detect known vulnerabilities within code and static configurations. They cannot predict live production challenges such as infrastructure configuration drift, insider threat behaviors, credential theft, or zero-day exploits discovered after deployment.
What are the primary tools used in Shift-Right Security?
Common open-source and enterprise tools include Falco for container runtime protection, Prometheus and Grafana for security metric visualization, ELK Stack (Elasticsearch, Logstash, Kibana) or Grafana Loki for centralized production log analysis, and various SIEM platforms for real-time alert correlation.
Does runtime monitoring slow down application performance?
If modern tools leveraging technologies like eBPF (such as Falco) are configured correctly, the system overhead is extremely low and practically imperceptible to end users. However, poorly configured monitoring tools or excessive un-optimized logging can introduce latency and increase cloud resource consumption.
What is Security Chaos Engineering?
Security Chaos Engineering is the practice of intentionally introducing controlled security disruptions (such as simulating a unauthorized credential login or a cloud configuration change) into a running production environment to verify that the monitoring systems, alerting paths, and defensive guardrails react correctly.
How does Shift-Right Security help in incident response?
It provides immediate, real-time alerts alongside detailed contextual system state data, process trees, and application logs. This allows incident response teams to instantly determine how an attacker gained entry, isolate the affected resources, and apply defensive patches before a minor incident escalates into a major data breach.
What is configuration drift, and how does shifting right fix it?
Configuration drift occurs when manual updates, emergency hotfixes, or automated script glitches cause the live state of production cloud infrastructure to diverge from the secure templates defined in Infrastructure as Code repositories. Shift-right tools continuously monitor infrastructure states and flag or automatically roll back unauthorized changes.
Can a beginner learn Shift-Right Security and DevSecOps?
Yes, anyone with a basic understanding of software principles or IT systems can learn these methodologies. Aspiring engineers typically begin by mastering fundamental Linux command-line concepts, learning container basics with Docker and Kubernetes, and practicing with open-source monitoring frameworks.
What roles are responsible for managing shift-right security operations?
Managing runtime security is a collaborative effort shared across DevSecOps Engineers, Site Reliability Engineers (SREs), Cloud Security Architects, and Security Operations Center (SOC) analysts.
How does shift-right security address zero-day vulnerabilities?
When a zero-day exploit emerges, no signature or code patch exists to block it initially. Shift-right security tools focus on behavioral tracking. If an exploit attempts to force an application to run unusual system commands or open unapproved network connections, the runtime engine blocks the abnormal behavior regardless of the underlying exploit mechanism.
What is alert fatigue, and how can engineering teams prevent it?
Alert fatigue occurs when monitoring systems generate a continuous stream of low-priority or false-positive notifications, overwhelming engineers and causing them to ignore critical warnings. Teams prevent it by progressively tuning alert thresholds, establishing clear baselines, and automating the triage of non-critical events.
Is Shift-Right Security only useful for cloud-native or containerized systems?
While highly popular in containerized microservices and Kubernetes environments, shift-right security methodologies are equally applicable to legacy virtual machines, bare-metal data centers, and serverless compute architectures where continuous log evaluation and runtime threat analysis remain critical.
What is the role of centralized logging in forensic investigations?
When a security incident occurs, attackers frequently attempt to modify or delete local system logs to hide their tracks. Centralized logging platforms continuously stream logs to an external, secure, immutable data repository, ensuring that engineers retain access to unaltered evidence to reconstruct the timeline of an intrusion.
How can I start practicing shift-right concepts today?
You can start by downloading open-source tools like Falco, Prometheus, and Grafana on a local computer or within a test environment. Configure a basic application, intentionally trigger an unauthorized system event or simulate a high-traffic anomaly, and practice building dashboards and alerts to detect the activity.
Final Thoughts
The rapid expansion of the cloud-native landscape has made it clear that software protection cannot stop the moment a deployment pipeline completes successfully. Relying solely on pre-deployment checks creates an incomplete defense posture. While shifting left is vital for removing known code defects early, Shift-Right Security in DevOps provides the real-time operational visibility, threat detection capabilities, and system resilience required to safeguard applications in a dynamic environment.
Production is the ultimate testing ground where real user traffic intersects with real-world threats. By implementing comprehensive runtime monitoring, deep security observability, centralized log analytics, and automated incident response paths, engineering teams can transition away from reactive crisis management toward proactive, self-healing system design. Security in modern DevOps is an ongoing, circular loop. Embracing shift-right methodologies ensures your organization’s defenses remain active, adaptive, and resilient every single second your software runs live.




Leave a Reply
You must be logged in to post a comment.