Introduction & Overview
In the rapidly evolving world of software development, security is no longer an afterthought but a critical component integrated throughout the development lifecycle. DevSecOps—the practice of embedding security into DevOps workflows—ensures that security is proactive, automated, and continuous. Central to this practice is the Common Vulnerabilities and Exposures (CVE) system, a standardized framework for identifying and cataloging software vulnerabilities. This tutorial provides an in-depth exploration of CVE in the context of DevSecOps, covering its concepts, integration, use cases, and best practices.
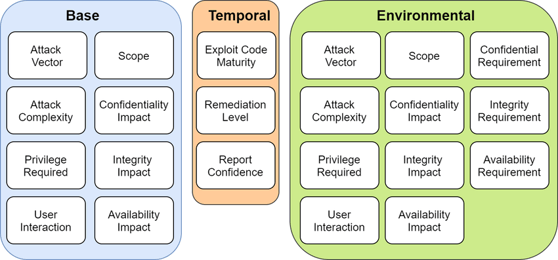
What is CVE (Common Vulnerabilities and Exposures)?
CVE is a dictionary of publicly disclosed cybersecurity vulnerabilities and exposures, maintained by the MITRE Corporation and sponsored by the U.S. Department of Homeland Security. Each CVE entry is assigned a unique identifier (e.g., CVE-2023-12345) and includes details about a specific vulnerability, such as its description, affected software, and potential impact.
- Purpose: Standardize vulnerability identification to facilitate communication, tracking, and remediation across organizations and tools.
- Scope: Covers vulnerabilities (flaws in software that can be exploited) and exposures (misconfigurations or weaknesses that may lead to vulnerabilities).

History or Background
The CVE system was launched in 1999 by MITRE to address the lack of a standardized naming convention for vulnerabilities. Before CVE, different vendors and researchers used proprietary names, leading to confusion and inefficiencies in vulnerability management.
- Key Milestones:
- 1999: CVE database established with initial entries.
- 2005: National Vulnerability Database (NVD) created by NIST, enhancing CVE with additional data like CVSS scores.
- 2016–Present: Expansion of CVE Numbering Authorities (CNAs) to include vendors like Microsoft, Red Hat, and others, improving global coverage.
- Current Status: As of 2025, the CVE database contains over 200,000 entries, with thousands added annually, reflecting the growing complexity of software ecosystems.
Why is it Relevant in DevSecOps?
In DevSecOps, security is integrated into every phase of the software development lifecycle (SDLC)—from planning to deployment and monitoring. CVE is critical because:
- Standardization: Provides a universal language for vulnerabilities, enabling consistent communication across development, security, and operations teams.
- Automation: CVE data feeds into vulnerability scanners and CI/CD tools, enabling automated detection and remediation.
- Compliance: Helps organizations meet regulatory requirements (e.g., GDPR, HIPAA) by tracking and addressing known vulnerabilities.
- Proactive Security: Allows teams to identify and patch vulnerabilities before they are exploited, aligning with DevSecOps’ “shift-left” philosophy.
Core Concepts & Terminology
Key Terms and Definitions
- CVE Identifier: A unique code (e.g., CVE-YYYY-NNNNN) assigned to a vulnerability or exposure. “YYYY” is the year, and “NNNNN” is a sequential number.
- Common Vulnerability Scoring System (CVSS): A framework to assess the severity of a CVE, with scores from 0–10 (e.g., 7.5 = High severity).
- National Vulnerability Database (NVD): A U.S. government repository that enriches CVE data with CVSS scores, references, and fix information.
- CNA (CVE Numbering Authority): Organizations authorized to assign CVE IDs, including MITRE, vendors, and security researchers.
- Vulnerability: A flaw in software or hardware that can be exploited to compromise a system.
- Exposure: A configuration or condition that increases the risk of a security breach, though not necessarily exploitable.
How it Fits into the DevSecOps Lifecycle
CVE integrates into the DevSecOps lifecycle at multiple stages:
- Planning: Use CVE data to assess risks in third-party libraries or software components before development begins.
- Development: Scan code and dependencies for known CVEs using tools like Dependabot or Snyk.
- Build: Integrate CVE scanning into CI/CD pipelines to catch vulnerabilities in artifacts before deployment.
- Deployment: Monitor production environments for newly disclosed CVEs affecting deployed software.
- Monitoring: Continuously track CVE feeds for updates and apply patches or mitigations as needed.
Architecture & How It Works
Components and Internal Workflow
The CVE ecosystem comprises several components:
- CVE List: The core database maintained by MITRE, containing CVE entries with identifiers, descriptions, and references.
- CNAs: Over 100 organizations worldwide assign CVE IDs to newly discovered vulnerabilities.
- NVD: Enhances CVE data with CVSS scores, exploitability metrics, and remediation details.
- Vulnerability Scanners: Tools like Nessus, Qualys, or Trivy query CVE/NVD data to identify vulnerabilities in systems or code.
- Security Information and Event Management (SIEM): Systems like Splunk or ELK integrate CVE data for real-time monitoring.
Workflow:
- A vulnerability is discovered by a researcher, vendor, or CNA.
- A CVE ID is assigned, and a record is created in the CVE List with details (e.g., affected software, impact).
- The NVD synchronizes with the CVE List, adding CVSS scores and additional metadata.
- DevSecOps tools query CVE/NVD data via APIs or feeds to scan systems and report vulnerabilities.
- Teams prioritize and remediate based on severity and context.
[CNA Reports CVE] → [MITRE Issues CVE-ID] → [NVD Enriches with CVSS, CPE] → [Scanners Detect in Code/Images] → [DevSecOps Pipelines Block/Flag]Architecture Diagram Description
The diagram is a flowchart with the following components, connected by arrows indicating data flow:
- Central Node: “CVE List (MITRE)” at the top, representing the core database.
- Connected Nodes: Multiple “CNA” boxes (e.g., Microsoft, Red Hat) feeding vulnerability data into the CVE List.
- NVD Node: Below the CVE List, connected by a bidirectional arrow, showing synchronization and enrichment.
- DevSecOps Tools Layer: Includes boxes for “CI/CD Tools” (e.g., Jenkins, GitLab), “Vulnerability Scanners” (e.g., Snyk, Trivy), and “SIEM” (e.g., Splunk), all querying the NVD via APIs.
- End Users: A “DevSecOps Team” box at the bottom, receiving alerts and reports from tools for remediation.
Developer Repo (GitHub/GitLab)
↓
CI/CD Pipeline
↓
[Static Analysis Tool] ←→ [CVE Database (NVD)]
↓
[Image/Dependency Scanner (e.g., Trivy)]
↓
Security Gate (Pass/Fail)
↓
Kubernetes / Cloud Deployment
Integration Points with CI/CD or Cloud Tools
- CI/CD Pipelines: Tools like Jenkins or GitHub Actions integrate CVE scanners (e.g., OWASP Dependency-Check) to scan dependencies during builds.
- Cloud Platforms: AWS Inspector, Azure Security Center, and GCP Security Command Center use CVE data to assess cloud workloads.
- Container Security: Tools like Trivy or Clair scan Docker images for CVEs in base images or libraries.
- APIs: NVD provides JSON feeds (e.g.,
https://nvd.nist.gov/vuln/data-feeds) for real-time CVE data integration.
Installation & Getting Started
Basic Setup or Prerequisites
To leverage CVE in a DevSecOps pipeline, you need:
- A vulnerability scanning tool (e.g., Trivy, Snyk, or OWASP Dependency-Check).
- Access to a CI/CD system (e.g., GitHub Actions, Jenkins, GitLab CI).
- A development environment with dependencies (e.g., Node.js, Python, or Docker).
- Optional: NVD API key for high-frequency queries (free registration at
https://nvd.nist.gov/developers/request-an-api-key).
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide demonstrates how to set up Trivy, an open-source vulnerability scanner, in a GitHub Actions pipeline to scan a Docker image for CVEs.
Step 1: Set Up a GitHub Repository
- Create a repository with a
Dockerfile(e.g., for a Node.js app):
FROM node:18
WORKDIR /app
COPY package.json .
RUN npm install
COPY . .
CMD ["npm", "start"]Step 2: Install Trivy Locally
- On Linux/Mac:
curl -sfL https://raw.githubusercontent.com/aquasecurity/trivy/main/contrib/install.sh | sh -s -- -b /usr/local/bin
- Verify installation:
trivy --version
Step 3: Create a GitHub Actions Workflow
- Add a
.github/workflows/scan.ymlfile:
name: CVE Scan
on:
push:
branches: [ main ]
jobs:
scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker Image
run: docker build -t my-app:latest .
- name: Scan with Trivy
uses: aquasecurity/trivy-action@master
with:
image-ref: 'my-app:latest'
format: 'table'
exit-code: '1' # Fail on critical vulnerabilities
severity: 'CRITICAL,HIGH'
Step 4: Run and Review
- Push the code to trigger the workflow.
- Check the GitHub Actions logs for CVE scan results, which list vulnerabilities with CVE IDs, severity, and affected packages.
Step 5: Automate Remediation
- Configure Dependabot or Renovate to update vulnerable dependencies automatically.
Real-World Use Cases
3 to 4 Real DevSecOps Scenarios
- Dependency Scanning in CI/CD:
- Scenario: A fintech company uses GitLab CI to build a Python application. Trivy scans the
requirements.txtfile and detects CVE-2023-32681 in therequestslibrary. - Action: The pipeline fails, alerting the team to upgrade to a patched version (
requests>=2.31.0). - Outcome: Prevents potential data exposure in production.
- Scenario: A fintech company uses GitLab CI to build a Python application. Trivy scans the
- Container Security in Kubernetes:
- Scenario: A healthcare provider deploys a microservices app on Kubernetes. Clair scans Docker images and identifies CVE-2024-12345 in an Alpine base image.
- Action: The team updates the base image to a secure version and re-deploys.
- Outcome: Ensures compliance with HIPAA by mitigating container vulnerabilities.
- Cloud Workload Protection:
- Scenario: An e-commerce platform uses AWS EC2 instances. AWS Inspector flags CVE-2023-45678 in the Apache server.
- Action: The team applies a security patch via AWS Systems Manager.
- Outcome: Maintains customer trust by securing web servers.
- Third-Party Library Auditing:
- Scenario: A gaming company uses Snyk to scan a Node.js app and finds CVE-2022-25883 in a vulnerable
semverpackage. - Action: Snyk suggests a compatible upgrade, which is applied via a pull request.
- Outcome: Reduces attack surface in a high-traffic application.
- Scenario: A gaming company uses Snyk to scan a Node.js app and finds CVE-2022-25883 in a vulnerable
Industry-Specific Examples
- Finance: Banks use CVE data to comply with PCI-DSS, scanning payment processing systems for vulnerabilities.
- Healthcare: Hospitals leverage CVE to secure medical IoT devices, ensuring patient data privacy.
- E-commerce: Retailers integrate CVE scans into CI/CD to protect customer-facing APIs from exploits.
Benefits & Limitations
Key Advantages
- Standardization: Universal CVE IDs simplify vulnerability tracking across tools and teams.
- Automation: Seamless integration with DevSecOps tools enables continuous security monitoring.
- Comprehensive Coverage: Thousands of vulnerabilities cataloged, covering diverse software and systems.
- Community Support: Backed by MITRE, NIST, and CNAs, ensuring reliability and updates.
Common Challenges or Limitations
- False Positives: Scanners may flag CVEs that are not exploitable in specific contexts.
- Data Overload: High volume of CVE entries can overwhelm small teams without prioritization.
- Lag in Updates: New vulnerabilities may take days to receive a CVE ID, delaying detection.
- Dependency on Tools: Effectiveness relies on the quality of scanning tools and their CVE database integration.
Best Practices & Recommendations
Security Tips, Performance, Maintenance
- Prioritize by Severity: Focus on CVEs with high CVSS scores (7.0+) or known exploits.
- Automate Scans: Integrate CVE scanning into every CI/CD stage to catch issues early.
- Patch Regularly: Use tools like Dependabot or Renovate to automate dependency updates.
- Monitor CVE Feeds: Subscribe to NVD feeds or vendor alerts for real-time updates.
- Contextual Analysis: Validate CVEs against your environment to reduce false positives.
Compliance Alignment, Automation Ideas
- Compliance: Map CVEs to frameworks like NIST 800-53 or ISO 27001 for audit readiness.
- Automation: Use GitHub Actions or Jenkins to fail builds on critical CVEs, ensuring zero-day vulnerabilities are addressed.
- Dashboards: Integrate CVE data into SIEM tools (e.g., Splunk) for centralized monitoring.
Comparison with Alternatives
| Feature/Tool | CVE-Based Tools (e.g., Trivy, Snyk) | Alternatives (e.g., OSV, Vendor Advisories) |
|---|---|---|
| Standardization | Universal CVE IDs ensure consistency | Proprietary or non-standard naming |
| Coverage | Broad, with 200,000+ entries | Limited to specific ecosystems or vendors |
| Integration | Native CI/CD and cloud integrations | Varies, often less seamless |
| Community | Backed by MITRE, NIST, CNAs | Community-driven or vendor-specific |
| Latency | Possible delay in CVE assignment | Faster for vendor-specific issues |
When to Choose CVE over Others
- Choose CVE-Based Tools: For cross-vendor, standardized vulnerability management in diverse software stacks.
- Choose Alternatives: When focusing on a specific ecosystem (e.g., Google’s OSV for open-source projects) or needing vendor-specific advisories.
Conclusion
CVE is a cornerstone of modern DevSecOps, enabling teams to identify, prioritize, and remediate vulnerabilities systematically. By integrating CVE data into CI/CD pipelines, cloud platforms, and monitoring systems, organizations can achieve proactive security and compliance. As software complexity grows, the role of CVE in DevSecOps will expand, with trends like AI-driven vulnerability prioritization and real-time exploit detection on the horizon.
Next Steps:
- Explore tools like Trivy or Snyk for hands-on CVE scanning.
- Subscribe to NVD feeds for real-time updates.
- Join DevSecOps communities to stay informed on best practices.









Leave a Reply
You must be logged in to post a comment.