Quick Definition (30–60 words)
Prevention is the proactive design, controls, and automation that stop faults, security incidents, and human error before they reach users. Analogy: Prevention is like a seatbelt, airbag, and guardrail ensemble for a car. Technical: Prevention minimizes incident likelihood by shifting detection and correction left in the system lifecycle and embedding controls in runtime.
What is Prevention?
Prevention is a discipline combining engineering, architecture, processes, and automation to reduce the probability and impact of adverse events in software systems. It is not simply detection or reactive troubleshooting. Prevention focuses on eliminating root causes, reducing blast radius, and making safe states the default.
Key properties and constraints:
- Proactive: acts before failure manifests.
- Measurable: tied to SLIs/SLOs and error budgets.
- Automated: uses policy-as-code and runtime enforcement where possible.
- Cost-aware: prevention can add complexity and cost; trade-offs are necessary.
- Composable: works across infrastructure, platform, CI/CD, and application layers.
Where it fits in modern cloud/SRE workflows:
- Left shift into design and CI/CD for safety checks.
- Runtime enforcement at control plane, service mesh, and WAF layers.
- Observability and telemetry feed continuous improvement loops.
- Integrated with security and compliance automation.
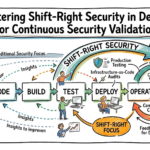
Diagram description (text-only):
- “User traffic enters edge proxies, passes policy gate; CD pipeline enforces pre-deploy tests; service mesh enforces circuit breakers and rate limits; observability collects metrics and traces; SLO controller gates deploys when error budget allows; incident playbooks trigger rollbacks and limit further blast radius.”
Prevention in one sentence
Prevention is the set of engineered controls and automations that reduce the chance of incidents and limit their impact by shifting safety checks earlier and enforcing policies at runtime.
Prevention vs related terms (TABLE REQUIRED)
| ID | Term | How it differs from Prevention | Common confusion |
|---|---|---|---|
| T1 | Detection | Detection finds incidents after they start | Treated as prevention |
| T2 | Mitigation | Mitigation reduces impact during incident | Mistaken for prevention alone |
| T3 | Remediation | Remediation fixes root cause post-incident | Confused with preventive fix |
| T4 | Resilience | Resilience focuses on recovery and tolerance | Seen as same as prevention |
| T5 | Observability | Observability provides signals and context | Assumed to prevent issues automatically |
| T6 | Security hardening | Hardening reduces attack surface selectively | Narrower than broad prevention |
| T7 | Compliance | Compliance enforces rules for auditability | Not always preventative in real-time |
Row Details (only if any cell says “See details below”)
- None
Why does Prevention matter?
Business impact:
- Revenue protection: fewer outages mean less direct revenue loss for e-commerce, subscriptions, or ad platforms.
- Customer trust: consistent availability and security maintain user confidence and reduce churn.
- Legal and regulatory risk reduction: proactive controls lower the chance of breaches and noncompliance fines.
Engineering impact:
- Reduced incident frequency reduces toil and increases developer velocity.
- Fewer emergency changes decrease risk of cascading failures.
- Clear preventive patterns let teams focus on features instead of firefighting.
SRE framing:
- SLIs/SLOs drive where prevention matters; prevention extends the SLO by lowering failure rate.
- Error budgets are consumed less rapidly with prevention; teams can spend more budget on launches.
- Toil is reduced by automating repetitive safety checks and rollbacks.
- On-call burden drops as incidents become less frequent and less severe.
Realistic “what breaks in production” examples:
- Bad schema migration that blocks writes.
- Misconfigured rate limit that throttles legitimate traffic.
- Dependency service reaches CPU saturation and propagates failures.
- Privilege escalation via misapplied IAM policy exposes data.
- Canary release with hidden bug rolled out globally.
Where is Prevention used? (TABLE REQUIRED)
| ID | Layer/Area | How Prevention appears | Typical telemetry | Common tools |
|---|---|---|---|---|
| L1 | Edge and network | Rate limits, WAF rules, geo blocks | Edge request rates and blocked counts | Load balancer, WAF, CDN |
| L2 | Service mesh | Circuit breakers and retry budgets | Latency, success rate, retry counts | Service mesh control plane |
| L3 | Application | Input validation and feature flags | Error rates, validation failures | App libraries, feature flagging |
| L4 | Data layer | Schema checks and safe migrations | DB error rate, migration duration | Migration tools, DB proxies |
| L5 | CI/CD | Pre-deploy tests and gating | Pipeline pass rates and test coverage | CI, pipeline orchestrator |
| L6 | Cloud infra | Typed IaC, policy-as-code, least privilege | Drift, IAM change events | IaC, policy engines |
| L7 | Observability | Alert thresholds and automated tickets | Alert counts and noise ratio | Monitoring, tracing tools |
| L8 | Security | Runtime protection and secrets vaulting | Audit logs and auth failures | Vault, runtime protection |
| L9 | Serverless/PaaS | Concurrency limits, cold-start mitigation | Invocation success and throttles | Platform controls, function config |
| L10 | Cost controls | Budget alerts and autoscale limits | Spend, request per dollar | Cost management tools |
Row Details (only if needed)
- None
When should you use Prevention?
When necessary:
- When user-facing SLAs or SLOs are strict.
- For systems handling sensitive data or regulated workloads.
- When failure impact is high (financial, safety, legal).
- For high-change-rate services where human error risk is elevated.
When it’s optional:
- Prototype or early-stage noncritical features.
- Internal tools with low user impact and rapid iteration needs.
When NOT to use / overuse it:
- Over-automating small projects increases cost and complexity.
- Too many preventative gates slow developer velocity unnecessarily.
- Excessive hardening without monitoring can mask hazardous failure modes.
Decision checklist:
- If customer impact is high and error budget is small -> prioritize prevention.
- If change velocity is high and toil is increasing -> add automation gates.
- If team size is small and product is experimental -> use lighter-weight controls.
Maturity ladder:
- Beginner: Basic pre-merge tests, feature flags, and basic SLOs.
- Intermediate: Policy-as-code, runtim e limits, canaries, service mesh policies.
- Advanced: Automated SLO-driven deploy gates, AI-assisted anomaly prevention, integrated chaos testing, cross-account policy enforcement.
How does Prevention work?
Components and workflow:
- Design-time controls: architecture reviews, threat models, schema contracts.
- CI/CD gates: unit/integration tests, static analysis, contract tests.
- Policy enforcement: IaC checks, policy-as-code, RBAC constraints.
- Runtime enforcement: service mesh limits, WAF, rate limits, circuit breakers.
- Observability feedback: SLIs, traces, telemetry feed ML/automated decision systems.
- Continuous improvement: postmortems, SLO tuning, remediation automation.
Data flow and lifecycle:
- Developer writes code -> CI runs tests and policy checks -> Deploy blocked or approved -> Runtime enforcers apply protection -> Observability reports SLI state -> SLO controller gates further deploys.
Edge cases and failure modes:
- Prevention automation itself fails or misfires and blocks valid deploys.
- Rules become stale and generate false positives.
- Performance overhead of checks causes increased latency.
- Operators disable preventive controls to meet a deadline, creating risk.
Typical architecture patterns for Prevention
- Policy-as-Code Gatekeeper: Use policy engine in CI and control plane to reject noncompliant changes. Use when compliance is required.
- Canary + Automated Rollback: Deploy to canary and automatically rollback on SLO breach. Use when changes can be validated against live traffic.
- Service Mesh Safety Layer: Apply circuit breakers, retry budgets, and rate limits centrally. Use for polyglot microservices.
- Typed Contracts and Consumer-Driven Contracts: Enforce schema and API contracts in CI. Use when many teams share APIs.
- Chaos-Then-Prevent Pipeline: Run targeted chaos experiments in staging to find weaknesses, then codify fixes as prevention. Use when mature SRE practices exist.
Failure modes & mitigation (TABLE REQUIRED)
| ID | Failure mode | Symptom | Likely cause | Mitigation | Observability signal |
|---|---|---|---|---|---|
| F1 | False positive block | Deploys fail unexpectedly | Overstrict policy rule | Provide bypass with approval and tune rules | Increased pipeline failures |
| F2 | Performance overhead | Increased latency | Runtime checks add CPU | Profile and move checks to edge or pre-deploy | CPU and latency spike |
| F3 | Rule drift | Controls outdated | No review cadence | Scheduled rule reviews and tests | Rising false positives |
| F4 | Automation outage | Prevention automation unavailable | Dependency failure | Fail open with manual approval path | Alert on automation health |
| F5 | Misconfigured limits | Legit traffic throttled | Incorrect thresholds | Dynamic thresholds and canaries | Throttle and 429 metrics |
| F6 | Shadow deploy blind spot | Prevention missed in prod | Canary tooling misconfigured | Verify promotion paths and telemetry | Canary vs prod divergence |
Row Details (only if needed)
- None
Key Concepts, Keywords & Terminology for Prevention
(Glossary of 40+ terms; each entry is a single line with three short parts separated by an em dash.)
Access Control — Rules controlling who/what can do actions — Reduces blast radius and privilege abuse — Pitfall: overly broad roles Adaptive throttling — Dynamically adjust rate limits by load — Prevents overload cascades — Pitfall: oscillation if thresholds poor Alert fatigue — Excessive alerts that reduce attention — Hinders response and masks true incidents — Pitfall: noisy thresholds Annotation — Metadata attached to resources or telemetry — Helps automate policy and ownership — Pitfall: inconsistent use Audit logs — Immutable record of actions — Required for forensics and compliance — Pitfall: not centralized or retained Auto-remediation — Automated fixes executed on detection — Reduces toil and MTTR — Pitfall: unsafe automation can worsen incidents Autoscaling safety — Scale policies that avoid spikes — Prevents resource exhaustion — Pitfall: scale loops and cost blowup Baselining — Establishing normal behavior profiles — Enables anomaly-based prevention — Pitfall: stale baselines Behavioral policy — Rules based on behavior patterns — Blocks suspicious actions proactively — Pitfall: false positives Canary deployment — Partial rollout to subset of traffic — Detects regressions before global release — Pitfall: insufficient traffic to validate Chaos testing — Controlled fault injection exercises — Finds unknown weaknesses to prevent incidents — Pitfall: lack of blast radius controls Circuit breaker — Fast fail mechanism for downstream errors — Prevents cascading failures — Pitfall: misconfigured thresholds Command controls — Approval gates and guardrails in CI/CD — Prevents risky actions by mistake — Pitfall: creates bottlenecks Contract testing — Ensures API compatibility between teams — Prevents runtime contract failures — Pitfall: incomplete test coverage Data validation — Input validation at boundaries — Prevents corruption and injection attacks — Pitfall: inconsistent validation across services Deadman switch — Fallback that triggers when health signals stop — Prevents uncontrolled operations — Pitfall: noisy triggers Defensive coding — Programming patterns that fail safely — Reduces unexpected panics — Pitfall: hides real errors Dependency pinning — Fixing versions to avoid breaking changes — Prevents unexpected updates — Pitfall: security patch lag Drift detection — Detecting configuration drift from desired state — Prevents outages from manual changes — Pitfall: noisy diffs Feature flags — Toggle features to control exposure — Prevents full rollout of risky changes — Pitfall: flag debt and complexity Formal verification — Mathematical proofs of correctness — Prevents certain classes of bugs — Pitfall: expensive and limited scope Health checks — Liveness and readiness probes — Enable safe routing and restarting — Pitfall: superficial checks that pass falsely IaC linting — Static checks on infrastructure as code — Prevents unsafe infra changes — Pitfall: false security complacency Immutable infrastructure — Replace rather than mutate instances — Prevents configuration drift and unknown state — Pitfall: requires deployment design Least privilege — Grant minimal necessary permissions — Prevents privilege abuse — Pitfall: overrestricting breaks automation Lifecycle policies — Rules for resource creation and deletion — Prevents stale or risky resources — Pitfall: accidental deletion ML-assisted prevention — Models that predict risky changes — Automates early warnings — Pitfall: model drift and bias Observability-driven dev — Use telemetry to shape prevention work — Keeps controls grounded in reality — Pitfall: overreliance on retrospective signals Policy-as-code — Encode governance in executable policies — Prevents human error in approvals — Pitfall: policy bugs and lack of testing Pre-deploy testing — Tests run before production promotion — Stops regressions early — Pitfall: not covering edge cases Rate limiting — Controls request throughput — Prevents overload and abuse — Pitfall: blocking legitimate bursts Rollback automation — Automatic revert on SLO breach — Limits blast radius — Pitfall: frequent flapping if thresholds tight Runtime attestations — Proofs about runtime state or identity — Prevents compromised workloads — Pitfall: added complexity Safe defaults — Conservative settings that avoid risk by default — Prevents accidental exposure — Pitfall: may hamper performance SLO controller — Automation that enforces SLO-aware decisions — Prevents over-deployment when budget exhausted — Pitfall: complexity of policies Shadow traffic testing — Run traffic against new code without affecting users — Finds issues without impact — Pitfall: insufficient similarity to real traffic Static analysis — Code analysis without running it — Prevents some classes of bugs — Pitfall: false positives and coverage gaps Traffic shaping — Control distribution of user requests — Prevents hotspots and overload — Pitfall: uneven user experience Type systems — Strong typing to prevent class of bugs — Prevents incorrect data misuse — Pitfall: added developer friction Vulnerability management — Detect and remediate vulnerabilities — Prevents exploit-based incidents — Pitfall: long remediation timelines Zero trust — Verify everything before trusting — Limits lateral movement — Pitfall: complexity and operational overhead
How to Measure Prevention (Metrics, SLIs, SLOs) (TABLE REQUIRED)
| ID | Metric/SLI | What it tells you | How to measure | Starting target | Gotchas |
|---|---|---|---|---|---|
| M1 | Prevention success rate | Percent of risky changes stopped | Blocked changes / total risky changes | 95% for critical policies | Under-reporting of risky changes |
| M2 | Preprod defect escape rate | Bugs reaching prod per deploy | Prod bugs / preprod bugs caught | <1 per 1000 deploys | Varies by app complexity |
| M3 | SLO breach count prevented | SLO breaches avoided by prevention | Compare baseline vs current SLOs | See details below: M3 | Needs baseline historical data |
| M4 | False positive rate | Percent of valid items blocked | False blocks / total blocks | <5% | Hard to label ground truth |
| M5 | Time-to-block resolution | Mean time to handle blocked deploy | Time from block to resolution | <1 hour for critical | Depends on on-call patterns |
| M6 | Automation availability | Uptime of prevention automation | Uptime percentage | 99% | Single automation outage causes disruption |
| M7 | Mean time to detect risky change | Time from risky change to flag | Median minutes | <5 minutes for CI policies | Instrumentation lag |
| M8 | Cost of prevention | Operational cost of prevention tooling | Monthly tooling and ops cost | Budget varies | Hard to attribute avoided incidents |
| M9 | Error budget burn rate | Rate of SLO consumption post-prevention | Error budget per time window | Keep burn <1x baseline | Dynamic traffic affects burn |
| M10 | Deployment velocity | Deploys per day with prevention | Deploys/day | Increase or steady with less incidents | Too many gates may reduce this |
Row Details (only if needed)
- M3: Compare a historical baseline period before prevention features to current period to estimate breaches avoided. Use controlled rollouts for more accurate attribution.
Best tools to measure Prevention
Use the following tool sections for practical guidance.
Tool — Prometheus / OpenTelemetry stack
- What it measures for Prevention: SLI metrics, latency, error rates, automation health.
- Best-fit environment: Cloud-native Kubernetes and microservices.
- Setup outline:
- Instrument services with OpenTelemetry metrics.
- Configure Prometheus scraping and recording rules.
- Create SLOs using metric-based queries.
- Export to long-term store if needed.
- Strengths:
- High flexibility and open standards.
- Good ecosystem for alerts and recording rules.
- Limitations:
- Operational overhead for scale.
- Needs long-term storage integration.
Tool — Cloud-native observability platform (vendor) — Var ies / Not publicly stated
- What it measures for Prevention: Aggregated SLIs, anomaly detection, alerting.
- Best-fit environment: Managed cloud services and enterprise setups.
- Setup outline:
- Ingest traces, logs, and metrics.
- Configure SLO and alert policies.
- Integrate CI/CD events.
- Strengths:
- Managed service reduces operational burden.
- Rich visualization and AI-assisted insights.
- Limitations:
- Cost and vendor lock-in considerations.
Tool — Policy engine (policy-as-code)
- What it measures for Prevention: Policy enforcement counts, rule violations, blocked changes.
- Best-fit environment: IaC pipelines and control planes.
- Setup outline:
- Define policies as code.
- Integrate into pre-merge and admission controllers.
- Capture violation telemetry.
- Strengths:
- Centralized governance.
- Testable and auditable rules.
- Limitations:
- Learning curve for policy language.
Tool — Feature flagging platform
- What it measures for Prevention: Exposure controls, successful rollouts, flag toggles.
- Best-fit environment: Teams managing controlled feature rollouts.
- Setup outline:
- Use flags for incremental exposure.
- Track flag state and metrics.
- Automate rollbacks based on SLOs.
- Strengths:
- Fast rollback and gradual exposure.
- Limitations:
- Flag debt and complexity in logic.
Tool — CI/CD with gating (pipeline orchestrator)
- What it measures for Prevention: Pipeline pass rates, blocked merges, test coverage.
- Best-fit environment: All teams with automated pipelines.
- Setup outline:
- Add static analysis, contract tests, and policy checks to pipelines.
- Emit metrics for blocked merges.
- Enforce gating rules.
- Strengths:
- Catches issues before deploy.
- Limitations:
- Pipeline time increases if tests are heavy.
Recommended dashboards & alerts for Prevention
Executive dashboard:
- Panels:
- High-level SLO compliance across products.
- Prevention success rate and false positive rate.
- Cost of prevention vs incident cost estimate.
- Why:
- Communicates prevention ROI and health to leadership.
On-call dashboard:
- Panels:
- Real-time SLO status and burn rate.
- Active blocked deploys and responsible owners.
- Automation health and policy failure counts.
- Why:
- Provides quick context and action items for responders.
Debug dashboard:
- Panels:
- Detailed traces and error logs for canary traffic.
- Recent policy violations and pipeline runs.
- Resource metrics around failing services.
- Why:
- Helps engineers rapidly identify root causes.
Alerting guidance:
- Page vs ticket:
- Page for SLO breaches or prevention automation outage impacting production.
- Ticket for policy violations that do not affect production.
- Burn-rate guidance:
- Alert when burn rate exceeds 4x baseline for critical SLOs and escalate at 8x.
- Noise reduction tactics:
- Dedupe alerts by grouping by root cause.
- Suppression windows during maintenance.
- Use fingerprinting and smart grouping.
Implementation Guide (Step-by-step)
1) Prerequisites – Ownership and sponsor identified. – Baseline telemetry available. – CI/CD and infra automation in place. – Defined SLOs for critical user journeys.
2) Instrumentation plan – Instrument key SLIs (latency, success rate, availability). – Add contract tests and schema checks. – Tag telemetry with deploy and pipeline metadata.
3) Data collection – Centralize logs, metrics, traces. – Retain audit and policy violation history. – Ensure low-latency pipelines for SLO evaluation.
4) SLO design – Define user-centric SLOs for key journeys. – Map prevention controls to SLOs they protect. – Set initial targets and review cadence.
5) Dashboards – Build executive, on-call, and debug dashboards. – Add panels for prevention metrics specifically.
6) Alerts & routing – Create alert playbooks: page for SLO breach, ticket for policy slip. – Route blocked deploy alerts to owners and secondary on-call.
7) Runbooks & automation – Author runbooks for blocked deploys and false positives. – Automate safe rollback and canary promotion based on SLOs.
8) Validation (load/chaos/game days) – Run load tests and chaos exercises in staging. – Verify prevention controls under failure. – Include human-in-the-loop for critical controls.
9) Continuous improvement – Review postmortems and SLO burn. – Rotate and audit policies. – Introduce ML-assisted detection when mature.
Pre-production checklist:
- CI gate tests passing consistently.
- Schema and contract tests in place.
- Simulated canary traffic run.
- Runbook for blocked deploys created.
Production readiness checklist:
- SLOs defined and monitored.
- Alerts and routing validated.
- Rollback / canary automation tested.
- On-call trained on prevention playbooks.
Incident checklist specific to Prevention:
- Identify which prevention control triggered.
- Assess if block was legitimate or false positive.
- If false positive, patch rule and unblock with audit.
- If legitimate, follow rollback and containment playbook.
- Record findings and adjust SLOs or controls.
Use Cases of Prevention
Provide 8–12 concise use cases.
1) Safe schema migrations – Context: Shared database across services. – Problem: Migration can block writes or corrupt data. – Why Prevention helps: Migration checks and schema compatibility prevent outages. – What to measure: Migration success rate and post-migration errors. – Typical tools: Migration tool with plan and prechecks.
2) Preventing runaway costs – Context: Auto-scaling unbounded instances. – Problem: Spike in traffic causing massive cost. – Why Prevention helps: Budget alerts and quota enforcement stop cost surprises. – What to measure: Spend vs budget and autoscale actions. – Typical tools: Cost management and autoscale policies.
3) Throttle abusive clients – Context: API exposed publicly. – Problem: One client overloads backend. – Why Prevention helps: Rate limits and IP blocking avoid service degradation. – What to measure: 429 rates and client request distribution. – Typical tools: API gateway, WAF.
4) Secure secret handling – Context: Multiple teams deploying apps. – Problem: Secrets exposed or misused. – Why Prevention helps: Vault and policy enforcement prevent credentials leakage. – What to measure: Secret access events and policy violations. – Typical tools: Secrets manager, policy-as-code.
5) Safe feature rollouts – Context: New feature release. – Problem: Feature introduces regression. – Why Prevention helps: Feature flags and canaries limit exposure. – What to measure: Error rate for flag groups and rollback rate. – Typical tools: Flagging platform and canary tooling.
6) Preventing config drift – Context: Manual changes in production. – Problem: Unexpected state causes failure. – Why Prevention helps: Drift detection reverts or alerts on unauthorized changes. – What to measure: Drift incidents and time to reconcile. – Typical tools: Desired state controllers.
7) Stopping privilege escalation – Context: IAM policy updates. – Problem: Overly permissive roles created. – Why Prevention helps: Policy linter rejects risky changes. – What to measure: Policy violations and blocked IAM edits. – Typical tools: Policy-as-code and CI gates.
8) Avoiding dependency outages – Context: Third-party API dependency. – Problem: Downstream degradation affects service. – Why Prevention helps: Circuit breakers and fallback reduce propagation. – What to measure: Downstream call success and circuit breaker trips. – Typical tools: Service mesh, retries with backoff.
9) Preventing promo misuse – Context: Promotional code systems. – Problem: Promo applied incorrectly or exploited. – Why Prevention helps: Validation and quota checks stop abuse. – What to measure: Fraud attempts and validation failures. – Typical tools: Rule engines and monitoring.
10) Preventing credential sprawl – Context: Long-lived access keys. – Problem: Keys leak and are abused. – Why Prevention helps: Rotate keys, enforce time-bound credentials. – What to measure: Key age and unauthorized usage. – Typical tools: Short-lived credentials and vaults.
Scenario Examples (Realistic, End-to-End)
Scenario #1 — Kubernetes: Canary rollout with SLO-driven automatic rollback
Context: Microservices running on Kubernetes with high traffic. Goal: Deploy new version with minimal risk using canary and auto-rollback. Why Prevention matters here: Prevents introducing regressions that violate SLOs. Architecture / workflow: CI builds image -> Deploys canary to 5% of pods -> Traffic split via ingress and service mesh -> Observability compares canary SLI vs baseline -> Auto-rollback policy triggers if canary breaches SLO. Step-by-step implementation:
- Add canary deployment manifest and ingress traffic split.
- Instrument canary with the same SLIs.
- Configure SLOs and set rollback thresholds.
- Implement controller to monitor and rollback. What to measure: Canary vs baseline latency and error rate, rollback frequency. Tools to use and why: Service mesh for traffic splitting; metrics system for SLOs; CI/CD for deploy automation. Common pitfalls: Insufficient canary traffic, noisy SLO signals leading to false rollbacks. Validation: Run synthetic traffic and chaos tests against canary. Outcome: Reduced production regressions and controlled deployments.
Scenario #2 — Serverless/PaaS: Preventing cold-start and throttling issues
Context: Event-driven serverless functions on managed PaaS. Goal: Prevent increased latency and invocation throttles. Why Prevention matters here: Improves user-facing latency and prevents lost events. Architecture / workflow: Pre-warm worker pools for critical functions, set concurrency limits, add DLQ for failed events, enforce throttling at ingress. Step-by-step implementation:
- Configure concurrency limits and reserved concurrency.
- Add warmers for critical paths.
- Monitor throttles and DLQ rates.
- Add automatic scaling rules and alerts. What to measure: Invocation latency, throttle rate, DLQ size. Tools to use and why: Platform concurrency settings, monitoring for invocation metrics. Common pitfalls: Over-prewarming increases cost, hard to simulate real traffic. Validation: Load tests and production pilot. Outcome: Fewer timeouts and consistent latency for critical flows.
Scenario #3 — Incident-response/postmortem: Preventing recurrence after root cause
Context: Production outage caused by misapplied configuration. Goal: Ensure incident does not recur by codifying prevention. Why Prevention matters here: Apply fixes that prevent human error repetition. Architecture / workflow: Postmortem identifies human step; introduce policy-as-code and CI gate to block similar changes. Step-by-step implementation:
- Record root cause and action item list.
- Implement a CI check to prevent risky config.
- Add audit logging and alerts for attempted changes.
- Train staff on new process. What to measure: Number of similar incidents after change, blocked attempts. Tools to use and why: Policy engine in CI, audit log aggregation. Common pitfalls: Incomplete policy coverage or bypassing process under pressure. Validation: Try to reproduce the error in staging to verify policy blocks. Outcome: Reduced recurrence and improved audit trail.
Scenario #4 — Cost/performance trade-off: Autoscale safety to avoid runaway costs
Context: Public-facing service scales horizontally based on traffic. Goal: Prevent cost explosions while maintaining performance. Why Prevention matters here: Balances SLOs with cost control. Architecture / workflow: Autoscaler with upper budget cap, predictive scaling, and cost alerts; fallback rate limits when budget threshold reached. Step-by-step implementation:
- Define budget thresholds and scale limits.
- Implement predictive scaling using historical trends.
- Enforce circuit breaker to reduce external calls during budget stress.
- Alert ops when budget thresholds near. What to measure: Cost per request, SLO compliance, scale events. Tools to use and why: Autoscaling policies, cost management tools. Common pitfalls: Tight caps cause SLO violations; predictive model errors. Validation: Simulate traffic spikes and evaluate SLO and cost interplay. Outcome: Controlled costs without persistent performance degradation.
Common Mistakes, Anti-patterns, and Troubleshooting
List of 20 common mistakes with Symptom -> Root cause -> Fix.
1) Symptom: Deployments blocked endlessly -> Root cause: Overstrict policy -> Fix: Add override path and tune policy. 2) Symptom: High alert noise -> Root cause: Low signal-to-noise thresholds -> Fix: Raise thresholds and add dedupe. 3) Symptom: False negatives in prevention -> Root cause: Incomplete test coverage -> Fix: Improve tests and contracts. 4) Symptom: Automation unavailable -> Root cause: Single point of failure in automation -> Fix: Add redundancy and fail-open path. 5) Symptom: Increased latency after controls -> Root cause: Runtime checks on hot path -> Fix: Move checks offline or to edge. 6) Symptom: Frequent rollbacks -> Root cause: Poor canary size or noisy SLOs -> Fix: Adjust canary traffic and refine SLO windows. 7) Symptom: Policy bypasses created -> Root cause: No audit or governance -> Fix: Enforce audit trail and limit bypass to emergency. 8) Symptom: Cost spike after prevention added -> Root cause: Over-prewarming or resource reservation -> Fix: Tune prewarming and reservations. 9) Symptom: Config drift not detected -> Root cause: Manual changes allowed -> Fix: Adopt desired state controllers. 10) Symptom: Secret leak incidents -> Root cause: Secrets in code or logs -> Fix: Move secrets to vault and scan repos. 11) Symptom: Observability blind spots -> Root cause: Missing instrumentation on critical paths -> Fix: Add OpenTelemetry instrumentation. 12) Symptom: RBAC too restrictive -> Root cause: Overzealous least-privilege -> Fix: Use role templates and progressive restriction. 13) Symptom: SLOs ignored by teams -> Root cause: Missing business mapping -> Fix: Educate and tie SLOs to customer journeys. 14) Symptom: Feature flag debt -> Root cause: Flags not removed post-launch -> Fix: Flag lifecycle management. 15) Symptom: Canary traffic not representative -> Root cause: Traffic routing misconfiguration -> Fix: Use realistic traffic mirroring. 16) Symptom: Drift in prevention rules -> Root cause: No scheduled reviews -> Fix: Quarterly policy audits. 17) Symptom: Failure to detect security issues -> Root cause: Limited runtime protection -> Fix: Add runtime attestations and detection. 18) Symptom: Slow remediation time -> Root cause: Missing runbooks -> Fix: Create and test runbooks. 19) Symptom: Metrics inconsistent across stacks -> Root cause: No metric standardization -> Fix: Define SLI naming and units. 20) Symptom: Overreliance on AI predictions -> Root cause: Poor model validation -> Fix: Human review and continuous retraining.
Observability-specific pitfalls (at least 5 included above):
- Missing instrumentation, noisy thresholds, inconsistent metrics, blind canary traffic, poor metric naming.
Best Practices & Operating Model
Ownership and on-call:
- Prevention owned by platform and product teams jointly.
- On-call rotations include prevention automation owners.
- Clear escalation paths for blocked deploys and policy failures.
Runbooks vs playbooks:
- Runbooks: step-by-step for known prevention events.
- Playbooks: higher-level decision trees for ambiguous cases.
Safe deployments:
- Canary releases with automated rollback.
- Gradual ramping and performance-based promotion.
- Feature flags for immediate kill switches.
Toil reduction and automation:
- Automate repetitive preventive checks and remediation.
- Use scripts and runbooks to reduce manual steps.
- Regularly review automation to avoid drift.
Security basics:
- Least privilege and policy-as-code.
- Runtime detection for anomalous behavior.
- Regular pentests and vulnerability scans.
Weekly/monthly routines:
- Weekly: Review blocked deploys and false-positive counts.
- Monthly: Policy rule audit and SLO compliance review.
- Quarterly: Chaos exercises and prevention roadmap planning.
What to review in postmortems related to Prevention:
- Whether existing prevention controls existed and failed.
- Whether controls caused the outage (false positive blocking).
- Actions to codify fixes into prevention rules.
- Measurement of prevention impact after remediation.
Tooling & Integration Map for Prevention (TABLE REQUIRED)
| ID | Category | What it does | Key integrations | Notes |
|---|---|---|---|---|
| I1 | Policy engine | Enforces policy-as-code in CI and runtime | CI, admission controllers | Test policies in unit tests |
| I2 | Observability | Collects metrics, logs, traces | CI, deploy metadata | SLO-driven decisions require low latency |
| I3 | CI/CD orchestrator | Runs tests and gating pipelines | VCS, policy engine | Keep pipeline time manageable |
| I4 | Feature flags | Controls feature exposure | Monitoring, CD | Track flag ownership and lifecycle |
| I5 | Service mesh | Runtime traffic control and resilience | Observability, ingress | Central place for circuit breakers |
| I6 | Secrets manager | Manages short-lived credentials | CI/CD, runtime | Rotate and audit secrets access |
| I7 | Migration tooling | Safe DB schema changes | DB, CI | Precheck migrations in staging |
| I8 | Cost manager | Enforces budgets and quotas | Cloud APIs, billing | Tie to prevention policies for autoscale |
| I9 | Chaos toolkit | Injects faults for testing | CI, staging | Limit blast radius and safety gates |
| I10 | LR( long-term store ) | Stores historical metrics for SLO | Observability systems | Needed for accurate baselining |
Row Details (only if needed)
- None
Frequently Asked Questions (FAQs)
What is the difference between prevention and mitigation?
Prevention stops issues before they reach users; mitigation reduces impact after issues occur. Both are needed but operate at different stages.
How do SLOs relate to prevention?
SLOs define acceptable user experience; prevention reduces the likelihood of SLO breaches and informs where prevention investment yields the most benefit.
Can prevention be fully automated?
Not fully; many checks can be automated, but human judgment is still required for unusual contexts and policy exceptions.
How do you balance prevention and deployment speed?
Use progressive gates like canaries and feature flags, automate low-risk checks, and reserve stricter controls for high-impact systems.
How much does prevention cost?
Varies / depends. Costs include tool licensing, engineering time, and potential compute overhead; balance against incident cost savings.
How do you measure prevention ROI?
Estimate incidents avoided and cost saved compared to prevention operational cost; use controlled experiments where possible.
What is policy-as-code?
A practice of expressing organizational policies in executable code that runs in CI and runtime to enforce rules consistently.
How do you prevent false positives?
Start with conservative rules, use real traffic in canaries, and maintain a feedback loop to tune rules quickly.
When should I use chaos testing?
When you have mature observability and automation and want to discover hidden weaknesses that prevention can address.
Is prevention just security?
No. Prevention covers reliability, performance, cost, and security concerns across the stack.
How do you avoid policy drift?
Schedule reviews, test policies in CI, and keep a change log for policy updates.
Should prevention be centralized or team-owned?
Hybrid model: platform provides standard policies; application teams own fine-grained rules for their services.
How to handle urgent production changes that bypass prevention?
Define emergency change processes with auditing and post-facto prevention actions to prevent recurrence.
What role does ML play in prevention?
ML can predict risky changes and detect anomalies, but models require validation and human oversight.
How do you prevent prevention from becoming a bottleneck?
Automate approvals for low-risk changes and limit manual review to high-risk decisions.
How often should prevention controls be tested?
Continuously via CI tests and at least quarterly via chaos and runbook drills.
What telemetry is most important for prevention?
SLIs tied to user journeys, policy violation counts, blocked deploys, and automation health.
How to prioritize which prevention to build first?
Start with highest-impact user journeys and the biggest incident causes identified in postmortems.
Conclusion
Prevention is a strategic investment that reduces incident frequency and impact by embedding safety into design, CI/CD, runtime, and operations. It requires measurable SLIs/SLOs, automation, and a culture of continuous improvement. Start small, measure impact, and scale prevention where business and SLO risks justify the cost.
Next 7 days plan:
- Day 1: Identify 3 critical user journeys and existing SLOs.
- Day 2: Audit CI/CD for missing pre-deploy checks and policy gaps.
- Day 3: Instrument key SLIs and tag deploy metadata.
- Day 4: Implement at least one policy-as-code rule in CI.
- Day 5: Configure a canary deployment for a non-critical service and observe.
- Day 6: Run a smoke chaos test in staging and record findings.
- Day 7: Draft runbooks for blocked deploys and schedule a policy review.
Appendix — Prevention Keyword Cluster (SEO)
Primary keywords:
- prevention in SRE
- preventive engineering
- proactive incident prevention
- prevention architecture
- prevention in cloud-native systems
- prevention automation
Secondary keywords:
- prevention best practices
- policy-as-code prevention
- SLO-driven prevention
- prevention in Kubernetes
- prevention for serverless
- prevention metrics
Long-tail questions:
- what is prevention in site reliability engineering
- how to implement prevention in CI CD pipelines
- how to measure prevention effectiveness with SLIs
- can prevention reduce on-call load
- how to add prevention to a microservices architecture
- how to balance prevention and deployment velocity
- what tools help prevention in Kubernetes
- how to prevent schema migration outages
Related terminology:
- canary rollback prevention
- policy enforcement CI
- runtime protection patterns
- prevention and error budgets
- prevention automation ROI
- prevention dashboards
- pre-deploy contract testing
- prevention runbooks
- prevention false positives
- prevention observability signals
- prevention failure modes
- prevention cheat sheet
- prevention maturity model
- prevention implementation guide
- prevention security integration
- prevention cost controls
- prevention telemetry
- prevention in IaC
- prevention in serverless platforms
- prevention vs mitigation
- prevention architecture patterns
- prevention for high availability
- prevention for regulated systems
- prevention for distributed systems
- prevention SLO examples
- prevention metrics examples
- prevention glossary
- prevention case studies
- prevention checklists
- prevention for cloud cost management
- prevention for dependency management
- prevention for API gateways
- prevention for feature flags
- prevention for secret management
- prevention for RBAC
- prevention for compliance automation
- prevention for chaos engineering
- prevention for anomaly detection
- prevention maturity ladder
- prevention playbooks
- prevention incident checklist
- prevention and ML
- prevention orchestration
- prevention observability tools
- prevention policy engine features
- prevention vs resilience
- prevention vs remediation
- prevention adoption strategy
- prevention enablement for teams
- prevention integration map
- prevention telemetry naming
- prevention metrics to track



Leave a Reply
You must be logged in to post a comment.