Quick Definition (30–60 words)
Disaster Recovery (DR) is the set of processes, architectures, and runbooks to restore service and data after a severe outage. Analogy: DR is the emergency evacuation map for a building after an earthquake. Formal: DR is a planned set of technical, operational, and verification controls to meet recovery time and recovery point objectives.
What is Disaster Recovery?
Disaster Recovery is the discipline of ensuring that critical systems and data can be recovered to an acceptable state after catastrophic events. It focuses on restoring availability, data integrity, and business continuity, not on routine incident remediation.
What it is / what it is NOT
- It is proactive planning, automation, and verification to recover from large-scale failures.
- It is NOT everyday incident response for single-service failures, though it overlaps with incident management.
- It is NOT just backups; backups are a core component but insufficient without orchestration, validation, and network/identity recovery.
Key properties and constraints
- Recovery Time Objective (RTO): how long acceptable downtime is.
- Recovery Point Objective (RPO): acceptable data loss window.
- Consistency and integrity: cross-service and transactional consistency.
- Dependence mapping: understanding upstream/downstream dependencies.
- Cost vs. risk: higher resiliency costs more; trade-offs required.
- Security and compliance: DR must preserve access controls and data residency constraints.
- Speed vs. complexity: faster recoveries typically require more automation and duplication.
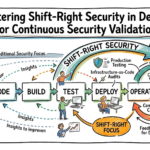
Where it fits in modern cloud/SRE workflows
- Strategy aligns with business continuity planning and risk assessments.
- Architecture level: multi-region, multi-cloud, or hybrid replication.
- SRE level: SLIs/SLOs define acceptable recovery behavior and error budgets drive investment in DR.
- CI/CD: DR runbook automation and infrastructure-as-code enable repeatable restoration.
- Observability and chaos engineering: validate DR readiness through drills and simulated failures.
- Security and IAM: ensure recovery does not violate least privilege or expose secrets.
A text-only “diagram description” readers can visualize
- Primary region running production services with replication pipelines sending data to warm secondary region; orchestration layer contains automated failover playbooks; DNS and load balancers configured for traffic shift; CI/CD stores IR artifacts and infrastructure-as-code templates; observability emits health SLIs and audit logs; runbook automation triggers security checks and secrets provisioning during failover.
Disaster Recovery in one sentence
Disaster Recovery is the practiced and automated plan that restores service and data integrity across systems to acceptable RTO and RPO targets following a catastrophic outage.
Disaster Recovery vs related terms (TABLE REQUIRED)
| ID | Term | How it differs from Disaster Recovery | Common confusion |
|---|---|---|---|
| T1 | Business Continuity | Focuses on ongoing business operations not only IT recovery | Often used interchangeably with DR |
| T2 | Backup | Data snapshot copy mechanism | Backups are a component of DR not the whole plan |
| T3 | High Availability | Minimizes single-node failures within region | HA is local and continuous; DR handles regional catastrophes |
| T4 | Fault Tolerance | System design to never fail for certain faults | Fault tolerance is more expensive than DR redundancy |
| T5 | Incident Response | Short term troubleshooting and mitigation | IR addresses incidents; DR restores whole service |
| T6 | Resilience Engineering | Practices to make systems robust | DR is a subset focused on recovery processes |
| T7 | Continuity of Operations | Government term for mission critical ops | Broader than IT DR and includes policy |
| T8 | Business Recovery | Focus on restoring business functions | Business Recovery includes non-technical activities |
| T9 | Cold Site | DR site type where infrastructure is provisioned after failover | Cold site is slower than warm or hot sites |
| T10 | Hot Site | DR site with live replication and immediate failover | Hot sites are costlier than warm or cold |
Row Details (only if any cell says “See details below”)
- None.
Why does Disaster Recovery matter?
Business impact
- Revenue: prolonged outages directly reduce revenue and conversion rates.
- Trust and brand: customer confidence erodes after visible data loss or downtime.
- Compliance and fines: regulatory violations can impose heavy costs.
- Insurance and contractual penalties: SLAs often include financial penalties for downtime.
Engineering impact
- Incident volume: DR planning reduces incident firefighting by having pre-defined recoveries.
- Velocity: clear recovery automation reduces developer time spent on ad-hoc restoration, freeing time for features.
- Complexity: DR planning forces dependency mapping, improving overall architecture hygiene.
SRE framing
- SLIs/SLOs: Define recovery SLIs like time-to-restore and data-loss rate; set SLOs that shape investment.
- Error budgets: Use error budget consumption during outages to reprioritize work.
- Toil: Automate repetitive recovery steps to reduce operational toil.
- On-call: On-call rotations must incorporate DR readiness for shift to recovery operations.
3–5 realistic “what breaks in production” examples
- Region-wide network partition causes database master lease to fail in primary region.
- Vendor outage disables identity provider, causing authentication failures across apps.
- Production schema migration corrupts replicated data, requiring rollback and coordinated recovery.
- Ransomware encrypts secondary storage snapshots, demanding rebuild from unaffected backups.
- Cloud provider control plane issue prevents provisioning of new compute in primary region.
Where is Disaster Recovery used? (TABLE REQUIRED)
| ID | Layer/Area | How Disaster Recovery appears | Typical telemetry | Common tools |
|---|---|---|---|---|
| L1 | Edge network | Failover of CDN and DNS to alternate POPs | Edge latency and cache hit ratios | CDN provider tools and DNS failover |
| L2 | Service mesh | Reconfigure routing between clusters | Service error rates and circuit breaker events | Service mesh control plane tools |
| L3 | Compute | Spin up instances in secondary region | Instance launch times and AMI health checks | IaaS orchestration and templates |
| L4 | Storage | Data replication snapshots and object versioning | Replication lag and snapshot success | Object storage and snapshot services |
| L5 | Databases | Cross-region replication and cluster failover | Replication lag and write errors | DB built-in replication or managed replicas |
| L6 | Serverless | Redeploy functions in alternative region | Invocation success rate and cold start times | Serverless deployments and backups |
| L7 | Kubernetes | Cluster state restore via manifests and PV rehydration | Pod health and persistent volume attach times | GitOps and cluster backups |
| L8 | CI/CD | Pipeline for redeploying infra and apps | Pipeline success and artifact availability | CI runners and artifact registries |
| L9 | Observability | Preserve and replicate logs and traces | Event ingestion rate and retention | Monitoring backends and log sinks |
| L10 | Security | Recovery of keys and IAM roles in new region | Auth errors and key rotations | Secret managers and IAM tooling |
Row Details (only if needed)
- None.
When should you use Disaster Recovery?
When it’s necessary
- Business impact from downtime or data loss exceeds cost of DR.
- Regulatory requirements mandate recovery capabilities.
- Multi-region deployments where single-region failure is a credible risk.
- Critical services with customer SLAs that include availability.
When it’s optional
- Non-critical internal tools with low business impact.
- Systems with small user base where manual recovery is acceptable.
- Early-stage startups where speed and cost trump guaranteed recovery.
When NOT to use / overuse it
- For every single microservice independently; cost and complexity explode.
- For feature flags and transient caches where simple rebuild is cheaper.
- When HA within region meets business needs and RTO/RPO are satisfied.
Decision checklist
- If revenue impact > threshold AND RTO < X hours -> implement automated DR.
- If only archival compliance is required -> backups with periodic restore tests.
- If multi-region latency constraints exist -> consider active‑active with data partitioning.
Maturity ladder: Beginner -> Intermediate -> Advanced
- Beginner: Daily backups, documented manual restore runbook, periodic restore tests.
- Intermediate: Automated backups, warm DR site, partial automation for failover, GitOps manifests.
- Advanced: Active‑active or fast failover, automated orchestration, chaos-tested DR drills, full playbooks and RBAC for recovery.
How does Disaster Recovery work?
Components and workflow
- Risk assessment and RTO/RPO definition.
- Infrastructure definition with redundant capacity or templates for secondary region.
- Data replication and snapshotting strategy.
- Orchestration for failover and failback (automation scripts, runbooks).
- DNS and traffic management for redirecting clients.
- Secret provisioning and IAM roles in the recovery environment.
- Observability to confirm system health during recovery.
- Validation: smoke tests, acceptance tests, and post-failover audits.
- Postmortem and improvement loop.
Data flow and lifecycle
- Source writes to primary datastore.
- Replication stream pushes changes to standby replicas or snapshot pipeline.
- Snapshots are periodically archived to immutable storage.
- During recovery, a restore job rehydrates data into target compute with integrity checks.
- State convergence: reconciliation jobs ensure cross-service consistency.
- After failback, data sync merges divergent writes according to reconciliation policy.
Edge cases and failure modes
- Split brain where both primary and secondary accept writes; requires conflict resolution.
- Partial corruption replicated to standby; immutable backups used for clean restore.
- Secrets or IAM not available in secondary region; fails post-provisioning steps.
- Dependencies on external SaaS vendor that lacks multi-region support.
Typical architecture patterns for Disaster Recovery
- Backup and Restore (Cold): Regular snapshots to durable storage; manual restore when needed. Use when cost sensitivity is high and RTO can be long.
- Pilot Light (Warm): Minimal critical services running in secondary region and scale up on failover. Good compromise for cost vs. speed.
- Warm Standby: Scaled-down production replica in secondary region that can scale up quickly. Suitable for moderate RPO/RTO.
- Active-Passive Multi-Region: Primary active, secondary passive with near real-time replication and automated failover.
- Active-Active Multi-Region: Both regions serve traffic with data partitioning or conflict resolution. Best for low RTO and high complexity tolerance.
- Cross-Cloud Provider DR: Replicate critical data across clouds to mitigate provider-specific control plane outages.
Failure modes & mitigation (TABLE REQUIRED)
| ID | Failure mode | Symptom | Likely cause | Mitigation | Observability signal |
|---|---|---|---|---|---|
| F1 | Replication lag | Secondary stale | Network congestion or overload | Throttle writes or add capacity | Replication latency metric |
| F2 | Backup corruption | Restore fails checksum | Bug or storage corruption | Use immutable storage and verify checksums | Snapshot verification failures |
| F3 | IAM failures | Auth errors on recovery | Missing roles in target region | Pre-provision roles and automate secrets | Auth error counts |
| F4 | DNS propagation delay | Users hit old site | DNS TTL high or caching | Reduce TTL and use failover DNS patterns | DNS TTL and traffic routing metrics |
| F5 | Split brain writes | Data divergence across regions | Dual writes without coordination | Implement leader election or reconciliation | Conflict detection alerts |
| F6 | Provisioning quotas | Fail to spin up resources | Cloud quota limits | Request higher quotas and pre-test provisioning | Provisioning failure logs |
| F7 | Configuration drift | Services misconfigured | Manual changes not in IaC | Enforce GitOps and drift detection | Config drift alerts |
| F8 | Third-party outage | Downstream errors | Vendor outage affects dependencies | Multi-vendor options or degrade gracefully | Downstream error rates |
| F9 | Secret leak in recovery | Unauthorized access | Improper secret management | Use secure secret stores and RBAC | Secret access audit logs |
| F10 | Observability gap | No telemetry in DR | Monitoring not replicated | Replicate metrics and logs with retention | Missing metrics and log gaps |
Row Details (only if needed)
- None.
Key Concepts, Keywords & Terminology for Disaster Recovery
- Recovery Time Objective (RTO) — Time target to restore service — Critical for cost vs speed decisions — Pitfall: set without measuring real impact.
- Recovery Point Objective (RPO) — Maximum acceptable data loss window — Drives replication frequency — Pitfall: assume zero RPO is free.
- Failover — Switching traffic to backup systems — Core action in DR — Pitfall: failing over without verifying data integrity.
- Failback — Returning to primary after recovery — Ensures long-term correctness — Pitfall: not reconciling divergent data.
- Warm Standby — Scaled-down replica ready to scale — Balances cost and availability — Pitfall: not regularly scaling tests.
- Hot Standby — Live replica with near-zero failover time — Low RTO but costly — Pitfall: hidden cross-region latencies.
- Cold Site — Infrastructure provisioned after failover — Low cost, high RTO — Pitfall: long provisioning time.
- Pilot Light — Minimal critical stack active in DR region — Rapid scale path — Pitfall: missing non-critical dependencies.
- Active-Active — Multiple regions serve traffic concurrently — High availability — Pitfall: data conflicts and complexity.
- Replication Lag — Delay between primary and standby — Affects RPO — Pitfall: ignoring tail latencies.
- Snapshot — Point-in-time backup of storage — Basis for restores — Pitfall: snapshot state inconsistent across services.
- Incremental Backup — Only changed data is saved — Saves cost and network — Pitfall: restore complexity.
- Immutable Backup — Backups cannot be altered — Protects against ransomware — Pitfall: retention management.
- Geo-redundancy — Data and services across regions — Reduces single-region risk — Pitfall: compliance constraints.
- Consistency Models — Strong, eventual consistency decisions — Affects correctness — Pitfall: choosing eventual without reconcilers.
- Leader Election — Determines authority for writes — Prevents split brain — Pitfall: unstable leader churn.
- DNS Failover — Using DNS to redirect traffic — Simple but TTL limited — Pitfall: DNS caching delays.
- Load Balancer Failover — Switch traffic at LB or edge — Faster than DNS — Pitfall: LB control plane limits.
- Chaos Engineering — Deliberate failure testing — Validates DR playbooks — Pitfall: insufficient guardrails.
- Runbook — Step-by-step recovery instructions — Plays for humans during DR — Pitfall: outdated runbooks.
- Playbook — Automated sequences for recovery — Orchestrates failover tasks — Pitfall: hard-coded values.
- Infrastructure as Code (IaC) — Declarative infra templates — Enables repeatable DR — Pitfall: secrets in code.
- GitOps — Git-driven desired states for clusters — Enforces consistency — Pitfall: not testing apply paths.
- Orchestration Engine — Automates DR steps — Coordinates multi-system recovery — Pitfall: single point of failure.
- Reconciliation — Process to fix divergent state — Ensures data correctness — Pitfall: complex merge logic.
- Snapshot Verification — Checks backup integrity — Prevents surprises — Pitfall: skipped due to time.
- Retention Policy — How long backups are kept — Balances cost and compliance — Pitfall: misaligned legal needs.
- Ransomware Protection — Immutable and offsite backups — Protects against tampering — Pitfall: recovery access control.
- Cross-Cloud DR — Use different cloud provider as target — Mitigates provider outage — Pitfall: inconsistent services.
- Quota Management — Ensures resources available in DR region — Essential for provisioning — Pitfall: not pre-requesting limits.
- Data Rehydration — Restoring data into live infra — Time-consuming step — Pitfall: underestimated time.
- Staging Validation — Pre-production smoke tests for DR runs — Ensures readiness — Pitfall: not running with production scale.
- Audit Trail — Record of recovery actions — For compliance and review — Pitfall: missing or incomplete logs.
- Blue-Green — Deploy new environment and switch traffic — Useful pattern for recovery — Pitfall: cost of duplicate environments.
- Canary — Gradual traffic migration during failover — Reduces risk — Pitfall: insufficient canary scope.
- Puppet/Ansible/Terraform — IaC and orchestration tools — Automate provisioning — Pitfall: tool lock-in.
- Secret Manager — Centralized secret storage — Needed for recovery auth — Pitfall: recovery requires secret access.
- Immutable Infrastructure — Replace rather than mutate systems — Eases recovery — Pitfall: stateful services require careful planning.
- Observability — Metrics, logs, traces used during recovery — Essential for confidence — Pitfall: gaps between regions.
- Error Budget — Tolerated reliability loss — Prioritizes DR investments — Pitfall: misused as excuse to defer fixes.
- Postmortem — Root cause analysis after incident — Drives DR improvements — Pitfall: lack of action items closure.
- SLA — Contractual availability targets — May drive DR requirements — Pitfall: SLAs without measurable SLOs.
- SLO — Operational targets for service reliability — Guides DR priorities — Pitfall: unrealistic SLOs.
How to Measure Disaster Recovery (Metrics, SLIs, SLOs) (TABLE REQUIRED)
| ID | Metric/SLI | What it tells you | How to measure | Starting target | Gotchas |
|---|---|---|---|---|---|
| M1 | Time to Recovery | Speed of service restoration | Time from failover start to validated traffic | < 1 hour for critical services | Starting target varies by business |
| M2 | Data Loss Window | Amount of data lost after recovery | Time difference between last accepted write and failover | < 5 minutes for critical data | Network spikes can increase window |
| M3 | Restore Success Rate | Probability of successful restore | Successful restores divided by attempts | 99% | Test frequency impacts metric |
| M4 | Failover Automation Coverage | Percent of steps automated | Automated steps divided by total runbook steps | > 80% | Complexity may limit automation |
| M5 | Orchestration Time | Time orchestration takes to enact failover | Measure orchestration start to end | < 10 minutes | External API rate limits affect time |
| M6 | Replication Lag | Latency for replicated data | Median and 95th percentile replication delay | < 1s to < 5s by needs | Tail latencies matter |
| M7 | Provisioning Success | Rate of successful resource provisioning | Successful provisionings over attempts | 99% | Cloud quotas cause failures |
| M8 | Observability Coverage | Percent of critical metrics/logs in DR | Items replicated to DR observability | 100% | Cost of replicating logs |
| M9 | Runbook Accuracy | Fraction of runbook steps matching actual actions | Audit compare after drills | 95% | Runbooks stale if not maintained |
| M10 | Security Posture During DR | Unauthorized access attempts during recovery | Failed auth attempts and audit alerts | Zero tolerant for breaches | Access controls must be in place |
Row Details (only if needed)
- None.
Best tools to measure Disaster Recovery
Tool — Prometheus
- What it measures for Disaster Recovery: Replication lag, failover durations, provisioning metrics
- Best-fit environment: Cloud-native, Kubernetes, hybrid
- Setup outline:
- Instrument critical services with exporters
- Configure remote write for long-term retention
- Create SLO rules and alerting
- Strengths:
- Highly flexible query language
- Integrates with alert managers
- Limitations:
- Long-term storage needs external systems
- Requires scaling for global telemetry
Tool — Grafana
- What it measures for Disaster Recovery: Dashboards for RTO/RPO, orchestration metrics, drill views
- Best-fit environment: Multi-cloud and hybrid visualizations
- Setup outline:
- Connect to Prometheus and logs
- Create executive and on-call dashboards
- Configure role-based access
- Strengths:
- Customizable panels and alerts
- Unified visualization for multiple sources
- Limitations:
- Requires data sources to be available in DR
- Alerting complexity at scale
Tool — Elastic Stack
- What it measures for Disaster Recovery: Log and trace replication, restore verification logs
- Best-fit environment: Organizations needing full-text search on logs
- Setup outline:
- Replicate indices or use cross-cluster replication
- Create restore verification queries
- Monitor ingestion and indexing errors
- Strengths:
- Powerful search and correlation
- Good for forensic analysis
- Limitations:
- Storage costs for long retention
- Cross-cluster replication complexity
Tool — HashiCorp Vault
- What it measures for Disaster Recovery: Secret availability and rotation status during recovery
- Best-fit environment: Multi-region secret management
- Setup outline:
- Configure replication and leasing policies
- Automate secret provisioning in DR runbooks
- Monitor secret access logs
- Strengths:
- Secure replication and audit logs
- Fine-grained policies
- Limitations:
- Operational complexity for replication
- Recovery requires access to master keys
Tool — Terraform / IaC
- What it measures for Disaster Recovery: Provisioning time and drift through plan/apply metrics
- Best-fit environment: Cloud-based infrastructure with IaC practices
- Setup outline:
- Store state securely and replicate state backends
- Test apply in DR test accounts
- Use plan outputs for timing estimates
- Strengths:
- Repeatable provisioning
- Versioned infra changes through VCS
- Limitations:
- Secrets handling must be externalized
- Statefile recovery is critical
Recommended dashboards & alerts for Disaster Recovery
Executive dashboard
- Panels:
- Overall service RTO vs SLO — shows health vs target
- Business impact estimate — estimated revenue at risk
- Incident timeline summary — key events and actions
- Runbook execution status — percent complete
- Why: Provides leadership context and confidence decisions.
On-call dashboard
- Panels:
- Live service health and error rates
- Replication lag and provisioning success
- Runbook next steps and automation status
- Active alerts with routing info
- Why: Supports responders with prioritized actionable data.
Debug dashboard
- Panels:
- Detailed replication streams and per-shard lag
- Resource provisioning logs and API errors
- Authentication and secret access logs
- Network connectivity and DNS propagation metrics
- Why: Enables deep troubleshooting during recovery.
Alerting guidance
- What should page vs ticket:
- Page for metrics that indicate immediate inability to serve traffic or automated failover failed.
- Ticket for degraded performance that doesn’t threaten SLA or immediate recovery.
- Burn-rate guidance:
- Use burn-rate policy for SLOs under degradation; escalate if burn-rate triggers sustained budget consumption.
- Noise reduction tactics:
- Deduplicate alerts by grouping similar signals.
- Suppress alerts during planned failover windows.
- Use dependability trees to prevent child alerts from paging when parent outage active.
Implementation Guide (Step-by-step)
1) Prerequisites – Business RTO/RPO and compliance requirements documented. – Inventory of critical services and dependency map. – IaC templates and access to secondary region accounts. – Observability and access to logs and metrics across regions. – Secret management and IAM roles preconfigured.
2) Instrumentation plan – Instrument replication lag, restore durations, provisioning status. – Add SLI exporters for recovery actions. – Ensure logs include trace IDs for recovery workflows.
3) Data collection – Configure replication streams and durable snapshot schedules. – Ensure offsite immutable backup copies exist. – Replicate observability data or maintain long-term retention storage.
4) SLO design – Define recovery SLIs like time-to-recover and data-loss window. – Set SLOs based on business targets and error budgets. – Decide alert levels and paging criteria.
5) Dashboards – Build executive, on-call, and debug dashboards. – Include runbook step progress and orchestration logs.
6) Alerts & routing – Configure alert thresholds, burn-rate monitors, and paging rules. – Set escalation and routing based on service ownership.
7) Runbooks & automation – Implement playbooks as code for common failovers. – Keep human-readable runbooks for complex decisions. – Automate verification and smoke tests.
8) Validation (load/chaos/game days) – Schedule regular DR drills and game days. – Use chaos engineering to simulate provider outages. – Validate full restores from backups quarterly or based on criticality.
9) Continuous improvement – Postmortem after every DR event and drill. – Update runbooks, automation, and dependencies. – Re-align SLOs with business needs.
Checklists Pre-production checklist
- RTO/RPO documented and approved.
- IaC deployed in secondary region.
- Secrets replicated and IAM roles available.
- Observability replicated or accessible.
- Restore from backup tested once.
Production readiness checklist
- Automated failover scripts tested.
- DNS TTLs set appropriately for failover.
- Quotas verified in DR regions.
- Runbooks reviewed and owners assigned.
- Scheduled drill calendar established.
Incident checklist specific to Disaster Recovery
- Confirm incident severity and invoke DR plan.
- Notify stakeholders and runbook owner.
- Execute automated playbooks where available.
- Verify data integrity after restore.
- Monitor SLOs and adjust routing as needed.
- Run postmortem and actions.
Use Cases of Disaster Recovery
1) Global e-commerce checkout – Context: Checkout must remain available during region outage. – Problem: Single-region DB master failure impacts payments. – Why DR helps: Provides alternate region with transactional consistency. – What to measure: RTO, RPO, transaction reconciliation errors. – Typical tools: DB replication, DNS failover, payment gateway fallback.
2) Financial trading platform – Context: Millisecond-sensitive operations with strict compliance. – Problem: Data loss and downtime cause regulatory fines. – Why DR helps: Ensures rapid recovery and audit trails. – What to measure: Time to reconciliation, audit log completeness. – Typical tools: Active-active replication, immutable backups, secure vaults.
3) SaaS multi-tenant app – Context: Multi-tenant data isolation and availability. – Problem: Tenant data corruption risks all customers. – Why DR helps: Restores tenant state with least disruption. – What to measure: Tenant RPO, restore success per tenant. – Typical tools: Per-tenant backups, object versioning, GitOps.
4) Healthcare records system – Context: Protected health information with retention laws. – Problem: Data loss leads to compliance violations. – Why DR helps: Ensures recoverability and auditability. – What to measure: Backup integrity, restore completeness. – Typical tools: Encrypted backups, cross-region replication, strong IAM.
5) SaaS analytics pipeline – Context: Large event streams and transient compute. – Problem: Pipeline failure causes data gaps. – Why DR helps: Reprocess from raw immutable event store. – What to measure: Event backlog size and reprocessing time. – Typical tools: Event storage like durable logs, replay tooling.
6) API gateway and auth provider – Context: Auth outage breaks all downstream apps. – Problem: Vendor identity provider outage. – Why DR helps: Secondary identity provider and cached tokens. – What to measure: Auth failure rate, token cache hit ratio. – Typical tools: Identity provider redundancy, token caching.
7) Serverless backend for mobile app – Context: Managed services across region fail. – Problem: Lack of direct control over provider backups. – Why DR helps: Ensure function deployment and data replication to another region. – What to measure: Cold start times and invocation success post-failover. – Typical tools: Function versioning, cross-region data replication.
8) Internal productivity tools – Context: Email, chat, CRM for employees. – Problem: Non-critical but affects productivity. – Why DR helps: Replace with lightweight alternatives during outage. – What to measure: Restoration time and user impact. – Typical tools: SaaS fallback plans, backup exports.
9) Media streaming service – Context: High traffic peaks and CDN reliance. – Problem: Origin outage causes CDN cache misses. – Why DR helps: Failover origin or prepopulate caches. – What to measure: Cache hit ratio and origin latency. – Typical tools: CDN configuration and multi-origin setup.
10) IoT fleet management – Context: Devices require command and control. – Problem: Region outage prevents device updates. – Why DR helps: Alternate command endpoints and queued command replay. – What to measure: Command delivery latency and replay success. – Typical tools: Message queuing with durable storage, multi-region endpoints.
Scenario Examples (Realistic, End-to-End)
Scenario #1 — Kubernetes Cluster Region Failure
Context: A production Kubernetes cluster in us-east-1 experiences a provider control plane outage. Goal: Restore app workloads in us-west-2 with minimal downtime and data loss. Why Disaster Recovery matters here: K8s control plane outage prevents scheduling and autoscaling; workloads and persistent volumes may be inaccessible. Architecture / workflow: GitOps stores manifests; cluster backups include etcd snapshots and PV snapshots to object storage replicated to us-west-2. Step-by-step implementation:
- Trigger DR playbook to provision cluster in us-west-2 via IaC.
- Restore etcd or reconcile state via GitOps to create deployments.
- Rehydrate PVs from snapshots into new persistent volumes.
- Recreate services and configure load balancers.
- Update DNS with health-check based failover. What to measure: Time to recover control plane, PV attach times, pod readiness. Tools to use and why: GitOps operator for manifests, snapshot controller for PVs, Terraform for infra, Prometheus for metrics. Common pitfalls: Missing secrets in target cluster, namespace quota limits, snapshot inconsistency. Validation: Smoke test endpoints, run integration tests, verify data integrity. Outcome: Cluster restored in target region with validated application state and minimal user impact.
Scenario #2 — Serverless Managed-PaaS Provider Outage
Context: A managed serverless provider has a region-wide outage affecting functions and managed DB. Goal: Restore critical endpoints by deploying functions to alternative region and switching database to read replica. Why Disaster Recovery matters here: Serverless is convenient but tied to provider region. Architecture / workflow: Code stored in CI artifacts, IaC defines function deployments in multiple regions, data replicated to cross-region read replicas. Step-by-step implementation:
- CI triggers deployment of functions to secondary region.
- Promote read replica to primary and apply migrations as needed.
- Update API gateway custom domain to route to new endpoints.
- Provision secrets and IAM roles in new region. What to measure: Cold start times, function success rate, promoted replica lag. Tools to use and why: CI system for artifacts, provider replication for DB, DNS failover. Common pitfalls: Cold start performance, vendor limits, broken integrations with region-specific services. Validation: End-to-end transaction tests and load verification. Outcome: Critical endpoints restored with acceptable performance but higher latency for some users.
Scenario #3 — Incident Response and Postmortem Driven Recovery
Context: A misapplied schema migration corrupts customer records. Goal: Reconcile corrupted data and restore consistent state with minimal downtime. Why Disaster Recovery matters here: Ensures clean recovery and audit trail for compliance. Architecture / workflow: Backups and change stream logs allow replaying transactions up to safe point. Step-by-step implementation:
- Freeze writes to affected tables.
- Restore serde of data from immutable backups into a staging environment.
- Run reconciliation scripts comparing backups to altered data and patch divergences.
- Gradual rollout of patches and verify via SLOs.
- Document steps and run postmortem. What to measure: Data divergence rate, restore time, correctness verification pass rate. Tools to use and why: Backup system, change data capture, data validation frameworks. Common pitfalls: Missing transaction ordering, incorrect reconciliation rules. Validation: Automated validation suite and manual sampling. Outcome: Customer data consistency restored and migration process improved to prevent recurrence.
Scenario #4 — Cost vs Performance Trade-off for Multi-Region DR
Context: An early-stage SaaS must balance cost and availability for customers worldwide. Goal: Implement a Pilot Light approach to satisfy RTO without prohibitive cost. Why Disaster Recovery matters here: Prevents catastrophic outages while controlling costs. Architecture / workflow: Minimal critical services in secondary region with read replicas and cached assets. Step-by-step implementation:
- Maintain essential databases warm with replication.
- Store artifacts and images in replicated object storage.
- Automate scale-up scripts to increase compute on failover.
- Train runbooks and schedule quarterly drills. What to measure: Scale-up time, cost per failover hour, RTO. Tools to use and why: Orchestration scripts, object storage replication, cost monitoring. Common pitfalls: Under-provisioning for peak failover demand, unrealistic cost forecasts. Validation: Simulated failover under expected peak loads. Outcome: Achieves acceptable recovery at a fraction of full hot standby cost.
Common Mistakes, Anti-patterns, and Troubleshooting
List of mistakes with symptom -> root cause -> fix (selected 20)
1) Symptom: Restore fails with checksum errors -> Root cause: Backup corruption -> Fix: Use immutable backups and verify checksums during backup. 2) Symptom: Replicas are minutes behind -> Root cause: Network throttling or misconfigured replication -> Fix: Increase bandwidth and tune replication concurrency. 3) Symptom: DR automation times out -> Root cause: Quota limits or API throttling -> Fix: Pre-request quotas and add retry/backoff logic. 4) Symptom: Secrets missing in DR -> Root cause: Secrets not replicated -> Fix: Automate secret replication and test access. 5) Symptom: DNS still points to failed region -> Root cause: High TTL or cache -> Fix: Lower TTL for critical records and use active failover DNS. 6) Symptom: Observability gaps in DR -> Root cause: Metrics/logs not replicated -> Fix: Replicate observability data and maintain retention. 7) Symptom: Split brain data -> Root cause: Dual writes without coordination -> Fix: Implement leader election or vector clock reconciliation. 8) Symptom: Manual runbook steps inconsistent -> Root cause: Outdated runbooks -> Fix: Automate runbooks and schedule regular reviews. 9) Symptom: Excessive cost for standby -> Root cause: Hot standby across all services -> Fix: Use pilot light for non-critical components. 10) Symptom: Slow PV rehydration -> Root cause: Large volume restore without parallelism -> Fix: Use streaming restores and parallel workers. 11) Symptom: Unexpected security breach during recovery -> Root cause: Over-permissive recovery roles -> Fix: Harden RBAC and just-in-time access. 12) Symptom: CI pipelines fail to deploy in DR -> Root cause: Artifact registry inaccessible -> Fix: Replicate artifact registry or use multi-region caches. 13) Symptom: Orchestration single point of failure -> Root cause: Central orchestrator only in primary region -> Fix: Make orchestrator multi-region or client-driven. 14) Symptom: Postmortem lacks actions -> Root cause: No accountability for improvements -> Fix: Assign owners and track closure. 15) Symptom: Alerts overwhelm on-call -> Root cause: Unfiltered alerting during failover -> Fix: Suppress non-actionable alerts and group related issues. 16) Symptom: Inconsistent IAM policies -> Root cause: Manual IAM changes in primary -> Fix: Manage IAM via IaC and replicate to DR. 17) Symptom: Performance degradation after failover -> Root cause: Secondary region not sized for peak -> Fix: Ensure scale-up plans and run capacity tests. 18) Symptom: Legal compliance breach after recovery -> Root cause: Data replication across prohibited regions -> Fix: Implement geo-fencing and residency-aware restores. 19) Symptom: Failure to recover third-party integrations -> Root cause: Vendor outage or rate limits -> Fix: Design graceful degradation and alternate vendors. 20) Symptom: Too many manual decision points -> Root cause: Lack of automation -> Fix: Automate routine steps and keep human steps minimal.
Observability pitfalls (at least 5 included above)
- Gaps in metrics replication leading to blind spots.
- Logs not available due to retention or cost cutoffs.
- Trace sampling inconsistent across regions, complicating causal analysis.
- Missing tagging and correlation IDs across services during recovery.
- Dashboards untested with DR data making panels misleading.
Best Practices & Operating Model
Ownership and on-call
- Assign DR owners per service group and a DR coordinator for cross-service orchestration.
- On-call rotations should include DR-trained personnel and clear escalation paths.
Runbooks vs playbooks
- Runbooks: Human-readable step-by-step guides for decision points.
- Playbooks: Automated sequences of tasks executed by orchestrators.
- Keep both in version control and link to each other.
Safe deployments
- Use canary and blue-green methods to reduce blast radius.
- Automate rollback for failed deployments.
- Require recovery validation as part of deployment gate for critical services.
Toil reduction and automation
- Automate repetitive recovery steps.
- Use IaC and GitOps to reduce manual provisioning errors.
- Pre-provision critical resources to avoid quota surprises.
Security basics
- Use least privilege for recovery roles and just-in-time access.
- Store recovery keys in secure secret manager with replication.
- Maintain audit trails for all DR actions.
Weekly/monthly routines
- Weekly: Validate key alarms and replication status.
- Monthly: Run partial restores and validate runbook steps.
- Quarterly: Full restores for high-criticality systems; review quotas and contracts.
What to review in postmortems related to Disaster Recovery
- Accuracy of root cause analysis and missed signals.
- Runbook gaps and automation failures.
- SLO breaches and error budget consumption.
- Financial and customer impact assessment.
- Concrete action items with owners and deadlines.
Tooling & Integration Map for Disaster Recovery (TABLE REQUIRED)
| ID | Category | What it does | Key integrations | Notes |
|---|---|---|---|---|
| I1 | Backup Storage | Stores immutable backups and snapshots | Object storage, snapshot services | Critical for restore |
| I2 | Replication Engine | Streams data to standby | Databases, object stores | Monitors lag |
| I3 | IaC Orchestrator | Provisions infra in DR | Cloud APIs and VCS | State storage must be replicated |
| I4 | DNS/Traffic | Controls traffic failover | CDN and load balancers | TTL impacts speed |
| I5 | Secret Manager | Stores and replicates secrets | IAM and orchestration | Must support replication |
| I6 | Observability | Metrics, logs, traces replication | Monitoring and logging backends | Needed for validation |
| I7 | Chaos Tooling | Simulates failures for drills | Orchestration and CI | Use carefully in production |
| I8 | Database Tools | Handle promotion and failover | DB engines and replicas | Must ensure consistency |
| I9 | CI/CD | Deploys artifacts to DR | Artifact registry and runners | Pipelines must be multi-region |
| I10 | Identity Provider | Manages auth redundancy | SSO providers and RBAC | Token caching helpful |
Row Details (only if needed)
- None.
Frequently Asked Questions (FAQs)
What is the difference between RTO and RPO?
RTO is allowable downtime; RPO is allowable data loss window. Both guide DR design and cost.
How often should backups be tested?
At minimum quarterly for critical systems; monthly if SLAs require higher assurance.
Is active-active always better than active-passive?
No. Active-active reduces RTO but increases complexity and risk of data conflicts.
Can I rely on a SaaS vendor for my DR?
Often yes for some components, but verify their RTO/RPO and have contingency plans if the vendor cannot recover.
How much does DR cost?
Varies / depends on architecture, RTO/RPO targets, and provider choices.
How to handle secrets during recovery?
Use secure secret managers with replication and just-in-time access for recovery operations.
What metrics should I alert on during a failover?
Failover automation failures, replication lag spikes, provisioning errors, and authentication errors.
Should DR be fully automated?
Aim for high automation; keep manual approvals for high-risk decisions but minimize human toil.
How to avoid split brain scenarios?
Use leader election, fencing, and quorum-based systems to prevent dual write situations.
How often to run game days?
Quarterly for critical services; semi-annually for mid-level; annually for low-criticality systems.
What are common DR mistakes?
Missing secret replication, insufficient quotas, untested backups, and stale runbooks.
Does DR include security considerations?
Yes; recovery must preserve authentication, authorization, and auditability.
How to balance cost and recovery speed?
Use pilot light or warm standby for intermediate cost; hot standby only for critical low RTO.
How to validate data integrity after restore?
Run deterministic validation suites, checksums, and sample audits against backups.
Can observability be part of DR?
Yes; replicating metrics and logs is essential for confident recovery.
What role does GitOps play in DR?
GitOps provides declarative state and repeatable application reconciliation, making recovery predictable.
How does multi-cloud DR differ from multi-region DR?
Multi-cloud handles provider control plane diversity but increases operational differences and testing needs.
What is the best way to handle vendor outages?
Plan for graceful degradation, alternate vendors, or cached functionality to maintain service.
Conclusion
Disaster Recovery is a strategic discipline combining architecture, automation, observability, and operations. It requires clear business targets, automated tooling, regular validation, and a culture of continuous improvement. Effective DR reduces downtime, preserves trust, and keeps engineers focused on value rather than firefighting.
Next 7 days plan
- Day 1: Document critical services and set RTO/RPO targets.
- Day 2: Inventory backups, secret stores, and quotas in secondary regions.
- Day 3: Add essential recovery SLIs to monitoring and a simple dashboard.
- Day 4: Implement or test one automation playbook for a critical failover step.
- Day 5: Run a partial restore test and record results for the postmortem.
Appendix — Disaster Recovery Keyword Cluster (SEO)
- Primary keywords
- Disaster Recovery
- Disaster Recovery plan
- Disaster Recovery strategy
- Disaster Recovery as a service
- Disaster Recovery architecture
- Disaster Recovery plan template
- Disaster Recovery best practices
- Disaster Recovery testing
- Disaster Recovery RTO RPO
-
Disaster Recovery automation
-
Secondary keywords
- DR runbook
- DR playbook
- DR orchestration
- DR drills
- DR validation
- DR for Kubernetes
- DR for serverless
- Multi-region disaster recovery
- Cross-cloud DR
-
Immutable backups
-
Long-tail questions
- How to build a disaster recovery plan for cloud-native apps
- What is the difference between RTO and RPO in disaster recovery
- How to test disaster recovery for Kubernetes clusters
- How to automate disaster recovery runbooks
- How to measure disaster recovery readiness with SLIs and SLOs
- How often should you run disaster recovery drills
- What are the best disaster recovery tools for cloud
- How to handle secrets during disaster recovery
- How to design disaster recovery for multi-tenant services
-
How to implement pilot light disaster recovery approach
-
Related terminology
- Backup and restore
- High availability
- Active active
- Active passive
- Pilot light
- Warm standby
- Hot standby
- Cold site
- Failover
- Failback
- Replication lag
- Snapshot verification
- Immutable snapshot
- GitOps
- Infrastructure as code
- Chaos engineering
- Observability replication
- Secret manager replication
- DNS failover
- Load balancer failover
- Cross-region replication
- Quota management
- Provisioning orchestration
- Recovery audit trail
- Postmortem
- Error budget
- Runbook automation
- Playbook orchestration
- Leader election
- Data rehydration
- Staging validation
- Canary failover
- Blue green
- Reconciliation
- Consistency models
- Ransomware protection
- Legal data residency
- Backup retention policy
- Provisioning success rate
- Observability coverage



Leave a Reply
You must be logged in to post a comment.