Quick Definition (30–60 words)
Security Awareness is the organizational capability to detect, understand, and respond to security risks driven by human behavior, system telemetry, and threat intelligence. Analogy: it is like a neighborhood watch program combined with CCTV and a rapid response team. Formal: a socio-technical program that integrates training, telemetry, automation, and processes to reduce human-driven security risk.
What is Security Awareness?
What it is:
- A program combining education, operational telemetry, process controls, and automation to reduce human-induced security incidents.
- It encompasses behavior change, tooling, and continuous measurement.
What it is NOT:
- Not only training slides or annual phishing tests.
- Not a one-off audit or a pure compliance checkbox.
- Not a substitute for secure architecture, encryption, or least privilege.
Key properties and constraints:
- Human-centered but measurable via telemetry.
- Continuous: requires feedback loops and iteration.
- Cross-functional: involves security, SRE, engineering, HR, and product.
- Must balance privacy, legal, and employee morale.
- Constraint: often limited by telemetry quality and organizational culture.
Where it fits in modern cloud/SRE workflows:
- Integrated into CI/CD gates, observability pipelines, incident response, and change management.
- Feeds into SLOs for security-related behavior like patching cadence, misconfiguration detection, and phishing click rates.
- Automates remediation steps to reduce toil and enforce guardrails.
Text-only “diagram description” readers can visualize:
- Actors: Users, Developers, SRE, Security team, Automation.
- Inputs: Training, Phishing simulations, Telemetry (logs, metrics, traces), Threat feeds.
- Core system: Behavior analytics, Policy engines, CI/CD gates, Runbooks.
- Outputs: Alerts, Automated remediations, Training nudges, Postmortems, SLO reports.
Security Awareness in one sentence
Security Awareness is the continuous socio-technical program that uses training, telemetry, automation, and governance to reduce human and process-driven security risk across cloud-native operations.
Security Awareness vs related terms (TABLE REQUIRED)
| ID | Term | How it differs from Security Awareness | Common confusion |
|---|---|---|---|
| T1 | Security Training | Focuses on formal learning modules not continuous telemetry | Mistaken as the whole program |
| T2 | Security Operations | Reactive ops work focusing on incidents | Confused with preventive awareness |
| T3 | Compliance | Rule enforcement and evidence for audits | Assumed to equal effective security |
| T4 | Threat Intelligence | External data about threats | Thought to be behavior change |
| T5 | Incident Response | Structured response to incidents | Confused as proactive awareness |
| T6 | Observability | Technical visibility into systems | Assumed to cover human behavior |
| T7 | Phishing Simulation | Specific test of email risk | Seen as sufficient measurement |
| T8 | IAM | Access control systems and policies | Mistaken as complete awareness solution |
| T9 | Security Engineering | Building secure systems | Thought to eliminate need for awareness |
| T10 | DevSecOps | Embeds security in development processes | Treated as only cultural change |
Row Details (only if any cell says “See details below”)
- None
Why does Security Awareness matter?
Business impact:
- Revenue: Incidents from credential theft or misconfigurations cause downtime and lost sales.
- Trust: Customer trust erodes after breaches leading to churn and reputational damage.
- Risk: Regulatory fines and legal exposure increase with repeated human-driven breaches.
Engineering impact:
- Incident reduction: Fewer security-related incidents means fewer paging events and less firefighting.
- Velocity: Automated guardrails and informed engineers reduce review cycles and rollbacks.
- Quality: Engineers who understand secure defaults produce fewer exploitable changes.
SRE framing:
- SLIs/SLOs: Define SLIs for security posture like patch coverage, time-to-detect, and time-to-remediate; set SLOs that balance risk and velocity.
- Error budgets: Use security-related error budgets for acceptable risk windows; if spent, trigger controls like freeze windows or focused hardening.
- Toil/on-call: Security Awareness reduces toil by automating repetitive remediation and providing clearer playbooks for on-call responders.
3–5 realistic “what breaks in production” examples:
- Misconfigured cloud storage bucket exposing PII due to developer using default settings.
- Compromised CI credentials leading to malicious pipeline artifacts.
- Developers committing secrets to a public repo causing unauthorized access.
- Late patching of a known vulnerability leading to an exploit in a container image.
- Phishing of an admin causing privilege escalation and infrastructure changes.
Where is Security Awareness used? (TABLE REQUIRED)
| ID | Layer/Area | How Security Awareness appears | Typical telemetry | Common tools |
|---|---|---|---|---|
| L1 | Edge and network | Operator training for firewall rules and DDoS playbooks | Flow logs WAF logs | WAF SIEM FW |
| L2 | Service and app | Dev training for secure defaults and code review nudges | App logs auth logs | SCA SAST RASP |
| L3 | Data | Policies for data handling and classification training | DB audit logs DLP alerts | DLP DB ACL tools |
| L4 | Cloud infra | IAM hygiene and IaC policy checks | Cloud audit trails infra drift logs | CSPM IaC scanners |
| L5 | Kubernetes | Pod security policies and RBAC training | K8s audit logs admission logs | K8s auditors OPA |
| L6 | Serverless/PaaS | Least privilege functions and secret management | Invocation logs secret access logs | Secret managers APM |
| L7 | CI/CD | Pipeline credential handling and artifact signing | Pipeline logs build artifacts | CI plugins SCA |
| L8 | Incident response | Tabletop drills and runbooks | Alert timelines postmortem notes | IR platforms ChatOps |
| L9 | Observability | Training on signal interpretation and alert handling | Traces metrics logs | APM tracing SIEM |
Row Details (only if needed)
- None
When should you use Security Awareness?
When it’s necessary:
- When employees interact with privileged systems or customer data.
- Before and during cloud migrations or large infrastructure changes.
- When regulatory or contractual requirements mandate behavior controls.
When it’s optional:
- Small internal tools with no external exposure and no sensitive data.
- Prototypes and experiments isolated from production.
When NOT to use / overuse it:
- Overloading engineers with mandatory long courses that ruin productivity.
- Using punitive measures without coaching, which destroys trust.
- When telemetry is so poor that measurements are meaningless.
Decision checklist:
- If service accesses PII AND multiple engineers access infra -> implement mandatory program.
- If service is prototype AND isolated with no sensitive data -> lightweight awareness.
- If error budget is low AND recurring misconfigurations happen -> escalate to automation first.
Maturity ladder:
- Beginner: Basic training, phishing tests, manual playbooks.
- Intermediate: Integrated telemetry into CI/CD, automated nudges, basic SLOs.
- Advanced: Real-time behavior analytics, automated remediation, SLO-driven enforcement, AI assistance for coaching.
How does Security Awareness work?
Components and workflow:
- Education content and simulated exercises produce behavioral changes.
- Telemetry collection from apps, infra, CI, email, and endpoints.
- Analytics and policies detect risky behaviors and misconfigurations.
- Feedback loops: automated nudges, CI gates, alerts to on-call, and tailored training.
- Measurement and SLOs drive prioritization and automation investments.
Data flow and lifecycle:
- Instrumentation emits telemetry -> centralized ingestion -> anomaly detection and correlation -> policy engine decides action -> action triggers alert, automation, or training -> results fed back into measurement and training content.
Edge cases and failure modes:
- False positives causing alert fatigue.
- Privacy concerns when monitoring employee behavior.
- Incomplete telemetry resulting in blind spots.
- Automation causing disruptions when misconfigured.
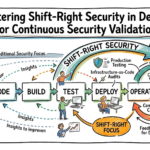
Typical architecture patterns for Security Awareness
-
Telemetry-first pattern: – Collect all security-related logs into a central lake and derive behavioral insights. – Use when you have mature logging and storage.
-
Policy-as-code pattern: – Encode security expectations into IaC and CI/CD gates. – Use when infrastructure is managed through IaC.
-
Nudge-and-train pattern: – Combine simulated phishing and contextual nudges in apps and IDEs. – Use when focusing on human behavioral change.
-
Automated remediation pattern: – Detect risky condition and run automated remediation with human-in-the-loop approvals. – Use when you can safely automate fixes.
-
SLO-driven enforcement: – Define security SLIs and tie enforcement to error budgets and release controls. – Use for balancing risk and velocity.
-
AI-assisted coaching: – Use ML models to surface risky code, PR comments, or infra changes and recommend fixes. – Use cautiously; requires strong privacy guardrails.
Failure modes & mitigation (TABLE REQUIRED)
| ID | Failure mode | Symptom | Likely cause | Mitigation | Observability signal |
|---|---|---|---|---|---|
| F1 | Alert fatigue | Ignored alerts | Too many false positives | Tune rules automate triage | Falling alert response rate |
| F2 | Blind spots | Missed incidents | Missing telemetry sources | Add instrumentation prioritize critical paths | Increase in undetected incidents |
| F3 | Privacy backlash | Employee resistance | Overly invasive monitoring | Anonymize data communicate policy | HR complaints metrics |
| F4 | Automation accidents | Mass rollbacks or outages | Bad remediation script | Safe rollout human approvals | Spike in change-failures |
| F5 | Training irrelevance | Low engagement | Generic content | Tailor to roles use contextual examples | Low completion and repeat fail |
| F6 | Siloed ownership | Slow response | No clear owner | Create cross-functional SLAs | Long MTTD and MTTR |
| F7 | Incomplete CI checks | Build-time breaches | Missing pipeline checks | Add policy-as-code and signing | Increase in vulnerable artifacts |
| F8 | Over-enforcement | Reduced velocity | Aggressive SLOs | Balance error budgets more conservatively | Higher rollback rates |
Row Details (only if needed)
- None
Key Concepts, Keywords & Terminology for Security Awareness
- Access control — Rules to permit or deny actions — Ensures least privilege — Pitfall: broad roles.
- Adversary emulation — Simulating attacks to test controls — Reveals gaps — Pitfall: unrealistic scenarios.
- Anomaly detection — Identifying unusual behavior — Early detection — Pitfall: many false positives.
- Application security — Security within app code — Prevents logic flaws — Pitfall: late-stage fixes.
- Attack surface — All points an attacker can use — Reducing it lowers exposure — Pitfall: ignoring indirect paths.
- Automated remediation — Scripts to fix known issues — Reduces toil — Pitfall: unsafe automation.
- Baseline behavior — Normal patterns for users/systems — Helps detect deviations — Pitfall: stale baselines.
- Behavioral analytics — Understanding user actions — Targets training — Pitfall: privacy concerns.
- Bug bounty — Outsourced testing via external researchers — Finds edge issues — Pitfall: scope mismanagement.
- Canary deployment — Gradual releases to limit blast radius — Safe rollouts — Pitfall: insufficient telemetry on canaries.
- CI/CD gates — Checks during build and deploy — Prevent insecure changes — Pitfall: slow pipelines.
- Cloud security posture management — Monitors cloud misconfigurations — Visibility for infra — Pitfall: noisy rules.
- Compromise indicators — Signals of breach — Faster response — Pitfall: ambiguous indicators.
- Credential hygiene — Management of passwords and keys — Reduces compromise risk — Pitfall: weak rotation policies.
- Data classification — Labeling data sensitivity — Guides controls — Pitfall: inconsistent classification.
- Deception techniques — Honeypots to detect intruders — Early detection — Pitfall: requires maintenance.
- DevSecOps — Embedding security into dev lifecycle — Shift-left security — Pitfall: poor integration.
- Drift detection — Detects infra divergence from desired state — Prevents config drift — Pitfall: noisy diffs.
- Encryption at rest — Protects stored data — Reduces data exposure — Pitfall: key management issues.
- Endpoint detection — Monitoring desktops and servers — Prevents lateral movement — Pitfall: agent coverage.
- Error budget — Allowed threshold of failures — Balances risk vs velocity — Pitfall: misuse for security.
- Event correlation — Linking multiple signals to an incident — Improves triage — Pitfall: under-correlated events.
- Governance — Policies and oversight — Ensures accountability — Pitfall: bureaucracy.
- Identity and Access Management — Control user permissions — Central to least privilege — Pitfall: privilege creep.
- Incident response — Structured steps to handle incidents — Limits damage — Pitfall: untested plans.
- Insider threat — Risk from authorized users — Hard to detect — Pitfall: privacy conflicts when monitoring.
- Least privilege — Minimal permissions for tasks — Reduces risk — Pitfall: operational friction.
- Machine learning security — Using ML for detection — Scales detection — Pitfall: model drift.
- Metrics and SLIs — Quantitative measures of behavior — Enables SLOs — Pitfall: picking irrelevant metrics.
- Multi-factor authentication — Additional verification step — Reduces credential theft — Pitfall: poor UX adoption.
- Observability — Visibility into systems via logs metrics traces — Fundamental for detection — Pitfall: gaps in coverage.
- Orchestration security — Security for schedulers and controllers — Prevents cluster-wide compromise — Pitfall: single control plane failure.
- Patch management — Keeping systems updated — Reduces exploitable vulnerabilities — Pitfall: testing delays.
- Phishing simulation — Testing email-based attacks — Measures human risk — Pitfall: unrealistic templates.
- Policy-as-code — Declarative enforcement of policy — Automated gating — Pitfall: complex rule conflicts.
- Postmortem — Analysis after incidents — Drives improvements — Pitfall: blame culture.
- Privileged access management — Controls high privilege accounts — Limits impact — Pitfall: bottlenecked approvals.
- Red team — Offensive testing team — Stress-tests defenses — Pitfall: lack of coordination with blue team.
- Role-based access control — Grants permissions based on roles — Simplifies management — Pitfall: role sprawl.
- Secret scanning — Detects credentials in code — Prevents leakage — Pitfall: false positives.
- Threat modeling — Anticipates attacker paths — Guides defenses — Pitfall: too academic without follow-up.
- Zero trust — Verify every request regardless of network — Reduces implicit trust — Pitfall: complex migration.
How to Measure Security Awareness (Metrics, SLIs, SLOs) (TABLE REQUIRED)
| ID | Metric/SLI | What it tells you | How to measure | Starting target | Gotchas |
|---|---|---|---|---|---|
| M1 | Phish click rate | Human susceptibility to phishing | Simulated phishing tests percent click | <5% | Cultural differences bias |
| M2 | Time to remediate misconfig | Speed of fixing infra mistakes | Mean time from detection to fix hours | <24h | Tooling gaps skew metric |
| M3 | Secrets in commits rate | Developer hygiene for secrets | Secret scan failures per 1000 commits | <0.1% | False positives in scans |
| M4 | Patch lag | Time to apply critical patches | Days since patch available | <7 days | Risk varies by asset |
| M5 | Privileged access audits | Frequency of privilege Reviews | Percent of accounts reviewed quarterly | 100% | Manual effort cost |
| M6 | CI policy violations | Pipeline security gate failures | Violations per 1000 builds | Decreasing trend | Rules may block valid builds |
| M7 | Mean time to detect (MTTD) | Detection capability | Time from compromise to detection hours | <4h | Blind spots increase value |
| M8 | Mean time to remediate (MTTR) | Response capability | Time from detection to containment hours | <12h | Dependency on on-call capacity |
| M9 | Security training completion | Engagement with training | Percent employees completed course | 95% | Completion != effectiveness |
| M10 | False positive rate | Alert quality | False alerts over total alerts percent | <20% | Labeling false positives is hard |
| M11 | Incidents from human error | Safety of processes | Incident count where root cause is human | Decreasing trend | Attribution variance |
| M12 | Policy drift rate | Infrastructure drift from desired state | Drift events per week | Near zero | Overly strict thresholds trigger noise |
Row Details (only if needed)
- None
Best tools to measure Security Awareness
Tool — SIEM (Security Information and Event Management)
- What it measures for Security Awareness: Detection of anomalous behaviors and correlation across sources.
- Best-fit environment: Medium to large cloud environments with diverse telemetry.
- Setup outline:
- Centralize logs and normalize events.
- Define security detection rules and enrichment.
- Integrate with identity and cloud audit logs.
- Strengths:
- Correlation across diverse signals.
- Supports compliance reporting.
- Limitations:
- Can be noisy and expensive at scale.
- Requires tuning and analyst expertise.
Tool — CSPM (Cloud Security Posture Management)
- What it measures for Security Awareness: Cloud misconfigurations and drift from best practices.
- Best-fit environment: Multi-account cloud deployments using IaC.
- Setup outline:
- Inventory cloud accounts and map configurations.
- Run continuous checks and prioritize findings.
- Feed findings into CI/CD gates.
- Strengths:
- Fast detection of common misconfigs.
- Maps well to IaC.
- Limitations:
- Rule sets may not cover custom infra.
- Potential for false positives.
Tool — Secret Scanning Tools
- What it measures for Security Awareness: Presence of keys and secrets in repositories and CI logs.
- Best-fit environment: Git-centric development teams.
- Setup outline:
- Install pre-commit hooks and CI scanning.
- Scan historical histories and PRs.
- Integrate with secret stores for rotation.
- Strengths:
- Prevents high-impact leaks early.
- Limitations:
- May produce false positives for test tokens.
Tool — Phishing Simulation Platforms
- What it measures for Security Awareness: Employee susceptibility and training efficacy.
- Best-fit environment: Organizations with email-based workflows.
- Setup outline:
- Configure realistic templates.
- Segment users by role and risk.
- Provide immediate feedback and tailored training.
- Strengths:
- Direct measurement of human risk.
- Limitations:
- May frustrate employees if poorly communicated.
Tool — Code Security Scanners (SAST, SCA)
- What it measures for Security Awareness: Vulnerable code and dependency risks.
- Best-fit environment: Teams with continuous integration.
- Setup outline:
- Integrate scanners into PR checks.
- Fail builds for critical issues or require remediation tasks.
- Track trends in dependency vulnerabilities.
- Strengths:
- Shift-left detection.
- Limitations:
- Can slow pipelines if not optimized.
Recommended dashboards & alerts for Security Awareness
Executive dashboard:
- Panels:
- Overall security SLO compliance and error budget.
- Trend of phishing click rates and training completion.
- Top 10 high-risk misconfigurations by severity.
- Recent incidents and containment time.
- Why: Provides C-suite a concise posture and trending risk indicators.
On-call dashboard:
- Panels:
- Active security alerts with priority.
- MTTD and MTTR for last 24 hours.
- Automated remediation queue and status.
- Relevant logs and recent related deployments.
- Why: Helps responders triage and act quickly.
Debug dashboard:
- Panels:
- Raw correlated events and related traces.
- User activity timelines and anomaly scores.
- IaC diff history and recent config changes.
- Secret-scan results for recent commits.
- Why: Provides deep context for investigation.
Alerting guidance:
- Page vs ticket: Page for active compromise indicators, escalation path, or failed remediation on critical assets. Create ticket for training reminders, low-priority misconfig findings, and non-blocking CI violations.
- Burn-rate guidance: Use error budgets on security SLOs to trigger controls; e.g., if error budget burn >2x baseline over 6 hours, temporarily block deployments to critical environments.
- Noise reduction tactics: Deduplicate similar alerts, group by affected resource, suppress noisy low-severity rules during known maintenance windows, and automatic suppression if an automated remediation is in progress.
Implementation Guide (Step-by-step)
1) Prerequisites – Inventory of users, services, and assets. – Centralized logging and identity data sources. – Baseline security policies and control owners. – Buy-in from leadership and HR/legal review.
2) Instrumentation plan – Identify telemetry: cloud audit logs, app logs, CI logs, email logs, endpoint telemetry. – Standardize schemas and enrich with context (team owner, service name). – Ensure retention policies align with legal and security needs.
3) Data collection – Centralize ingestion into SIEM or analytics lake. – Normalize and label events for correlation. – Apply data minimization and anonymization where needed.
4) SLO design – Choose measurable SLIs (see table above). – Define SLOs with realistic targets and error budgets. – Set escalation rules tied to error budget burn.
5) Dashboards – Build executive, on-call, and debug dashboards. – Expose SLO status prominently. – Provide links from dashboards to runbooks and tickets.
6) Alerts & routing – Map alerts to on-call rotations and responders. – Define page vs ticket thresholds. – Integrate ChatOps for rapid collaboration.
7) Runbooks & automation – Create clear runbooks for common security incidents. – Automate low-risk remediations; require approvals for high-impact actions. – Version control runbooks and test them.
8) Validation (load/chaos/game days) – Run chaos exercises that include adversary scenarios. – Conduct tabletop exercises and red team engagements. – Validate automation and runbooks in staging.
9) Continuous improvement – Postmortems after incidents and drills. – Iterate on training content and detection rules. – Invest in telemetry coverage based on incident patterns.
Checklists:
Pre-production checklist:
- Inventory pinned and owners assigned.
- CI/CD gates for secrets and policy checks enabled.
- Minimal telemetry flows validated.
- Runbooks written for common misconfigs.
Production readiness checklist:
- Dashboards and alerts configured.
- On-call roles trained and alerted.
- Automated remediations scoped and tested.
- SLOs enabled and baseline measured.
Incident checklist specific to Security Awareness:
- Triage: Validate alert validity and scope.
- Contain: Apply temporary controls or revocations.
- Communicate: Notify impacted owners and leadership.
- Remediate: Execute automated or manual fix.
- Postmortem: Document root cause and corrective actions.
Use Cases of Security Awareness
1) Cloud storage misconfiguration – Context: Publicly exposed buckets. – Problem: Data exfiltration risk. – Why Security Awareness helps: Detects risky changes and trains devs to avoid defaults. – What to measure: Time to remediation and exposure duration. – Typical tools: CSPM, SIEM, DLP.
2) Phishing risk reduction – Context: Email-based credential compromise. – Problem: Admin credentials stolen. – Why: Measures human risk and targets training. – What to measure: Phish click rate and re-click after training. – Typical tools: Phishing simulation, IAM.
3) CI credential leak prevention – Context: Secrets in pipeline logs. – Problem: Compromised CI leading to artifact poisoning. – Why: Prevents leaks and automates rotation. – What to measure: Secrets in commits rate and time to rotate. – Typical tools: Secret scanning, CI plugins.
4) Kubernetes privilege creep – Context: Excessive RBAC permissions. – Problem: Lateral movement in cluster. – Why: Detects role changes and trains SREs. – What to measure: Privileged access audits and drift rate. – Typical tools: K8s auditors OPA.
5) Shadow IT detection – Context: Unapproved tools and SaaS usage. – Problem: Data leakage and unmanaged access. – Why: Awareness identifies and educates owners. – What to measure: Number of unmanaged SaaS instances. – Typical tools: CASB SIEM.
6) Patch and vulnerability management – Context: Delayed patching across nodes. – Problem: Exploitable windows. – Why: Awareness ties ownership to SLIs and automates reminders. – What to measure: Patch lag and percent critical patched. – Typical tools: Patch management CSPM.
7) Insider threat detection – Context: Suspicious data access patterns. – Problem: Unauthorized data exfiltration by employees. – Why: Behavioral analytics surface anomalies and trigger reviews. – What to measure: Anomaly score trend and unauthorized exports. – Typical tools: DLP SIEM.
8) Third-party risk management – Context: Integrations and dependencies. – Problem: Vulnerabilities in vendor components. – Why: Awareness extends to procurement and dev teams for vetting. – What to measure: Percent of critical dependencies with fixes. – Typical tools: SCA vendor risk platforms.
9) Automated remediation safety – Context: Auto-fix of misconfigs. – Problem: Broken services from naive scripts. – Why: Awareness ensures human-in-loop approval patterns. – What to measure: Automation failure rate and rollback incidents. – Typical tools: Orchestration tools CI/CD.
10) Post-incident behavior change – Context: Repeat misconfig incidents. – Problem: Recurrence of same mistakes. – Why: Feedback loops convert incidents into tailored training. – What to measure: Recurrence rate after postmortem. – Typical tools: IR platforms LMS.
Scenario Examples (Realistic, End-to-End)
Scenario #1 — Kubernetes RBAC misconfiguration leads to data exposure
Context: A dev team grants broad cluster-admin role to a service account for testing. Goal: Prevent privilege escalation and detect risky role changes. Why Security Awareness matters here: Human decisions led to high-risk role assignment; awareness prevents recurrence. Architecture / workflow: K8s audit logs -> central SIEM -> RBAC anomaly detection -> CI policy enforcement for role creation -> training nudge for team. Step-by-step implementation:
- Enable K8s audit logging and send to SIEM.
- Implement admission controller to deny broad roles by default.
- Add IaC policy checks for RBAC resources.
- Create alert for any post-deploy RBAC changes and runbook.
- Schedule role review cadence and training for owners. What to measure: Number of broad roles created, time to revoke, RBAC drift rate. Tools to use and why: K8s auditors, OPA, SIEM, IaC scanners. Common pitfalls: Admission controllers might break older workflows. Validation: Run chaos test assigning temporary roles and verify detection and remediation. Outcome: Reduced RBAC-related incidents and faster remediation.
Scenario #2 — Serverless function leaking secrets via logs (Serverless/PaaS)
Context: Lambda-style functions log environment variables for debugging. Goal: Prevent secret leakage and automate detection. Why Security Awareness matters here: Developer habit led to leaks; telemetry can detect and stop it. Architecture / workflow: Function logs -> log parser -> secret scanner -> automated alert + sanitized logs -> mandatory remediation in PRs. Step-by-step implementation:
- Add runtime log scrubbing library and linters.
- Scan logs for patterns and integrate with SIEM.
- Block deployments if secret patterns found in commits.
- Provide training on secure logging. What to measure: Secrets found in logs per week and time to sanitize logs. Tools to use and why: Secret scanner, serverless observability, CI scanning. Common pitfalls: Overzealous scrubbing breaking legitimate logging. Validation: Simulate secret emission and confirm detection and remediation. Outcome: Fewer leaked secrets and automated fixes in pipelines.
Scenario #3 — Postmortem driven behavior change (Incident-response/postmortem)
Context: Repeated service degradation due to misapplied firewall rule changes. Goal: Institutionalize learning to prevent recurrence. Why Security Awareness matters here: Human change caused outages; awareness converts incident into control changes. Architecture / workflow: Change logs -> incident timeline -> root cause analysis -> new CI gating and training -> SLO adjustments. Step-by-step implementation:
- Run postmortem and identify change control gaps.
- Create automated pre-change validation scripts.
- Add training for network operators and a checklist.
- Monitor change-related incident rate for 90 days. What to measure: Incidents tied to change vs baseline. Tools to use and why: Change management, SIEM, CI hooks. Common pitfalls: Blame culture reduces reporting. Validation: Mock change in staging and ensure gate blocks risky config. Outcome: Reduced change-related incidents and better change hygiene.
Scenario #4 — Cost vs security trade-off when enabling deep telemetry (Cost/performance trade-off)
Context: Full-fidelity logging increases cloud costs and latency. Goal: Balance telemetry coverage with cost while maintaining detection. Why Security Awareness matters here: Insufficient telemetry causes blind spots; too much creates cost problems. Architecture / workflow: Sampling policies -> tiered retention -> critical path full-fidelity -> aggregate metrics for non-critical paths. Step-by-step implementation:
- Identify critical assets for full-fidelity retention.
- Apply sampling on low-risk flows.
- Route critical events to long-term storage and cheaper cold storage for compliance.
- Educate teams on telemetry priorities. What to measure: Coverage of critical paths, telemetry cost per detection. Tools to use and why: Observability platforms, cost monitoring tools. Common pitfalls: Sampling removes signals needed for root cause. Validation: Compare detection rates before and after sampling. Outcome: Controlled telemetry costs with maintained detection on critical assets.
Scenario #5 — Compromised CI service causes malicious artifact publication (Kubernetes or general)
Context: CI admin credentials exposed in a repo. Goal: Detect and contain artifact tampering quickly. Why Security Awareness matters here: Developer practices allowed credentials leakage; awareness reduces blast radius. Architecture / workflow: Secret scanning in repo -> artifact signing -> SBOM and registry monitoring -> alert on anomalous publish -> revoke keys and rotate. Step-by-step implementation:
- Enable secret scanning pre-commit.
- Implement artifact signing and SBOM generation.
- Monitor registry for unsigned or unexpected artifacts.
- Conduct emergency rotation automation for compromised keys. What to measure: Time from unauthorized publish to detection. Tools to use and why: Secret scanners, artifact registries, SBOM tooling. Common pitfalls: Legacy CI systems may be hard to retrofit. Validation: Simulate compromised key and ensure automated revocation works. Outcome: Faster containment and reduced trust erosion.
Common Mistakes, Anti-patterns, and Troubleshooting
- Symptom: High phish click rate -> Root cause: Generic, infrequent training -> Fix: Role-based, contextual short modules.
- Symptom: Alert fatigue -> Root cause: Un-tuned detection rules -> Fix: Prioritize signals, tune thresholds.
- Symptom: Excessive false positives in SIEM -> Root cause: Poor enrichment and correlation -> Fix: Add contextual fields and reduce noisy rules.
- Symptom: Missed incidents -> Root cause: Telemetry blind spots -> Fix: Inventory sources and instrument critical paths.
- Symptom: Automation causes outages -> Root cause: No human-in-loop for high-impact remediations -> Fix: Add approvals and safe rollbacks.
- Symptom: Low training completion -> Root cause: Poor incentives and poor UX -> Fix: Micro-training and integrate into workflows.
- Symptom: Recurrent misconfigurations -> Root cause: No IaC policies -> Fix: Policy-as-code and CI checks.
- Symptom: Slow patching -> Root cause: Manual patch workflows -> Fix: Automate patching and create SLOs.
- Symptom: Blame culture after incidents -> Root cause: Postmortems used to punish -> Fix: Blameless postmortems and learning actions.
- Symptom: Privilege creep -> Root cause: No periodic access reviews -> Fix: Automate privileged access reviews.
- Symptom: High noise from phishing platform -> Root cause: Overly aggressive templates -> Fix: Calibrate difficulty and communicate purpose.
- Symptom: Unapproved SaaS usage -> Root cause: No procurement checklist -> Fix: Integrate security review in procurement.
- Symptom: Detection model drift -> Root cause: ML models not retrained -> Fix: Schedule retraining with recent labeled data.
- Symptom: Cost blowup from logs -> Root cause: Wire-level capture for everything -> Fix: Tiered retention and sampling.
- Symptom: Developers override security gates -> Root cause: Gates that block critical work -> Fix: Provide temporary bypass with audit and limited window.
- Symptom: Runbooks stale -> Root cause: No review cadence -> Fix: Include runbook reviews in postmortems.
- Symptom: Unclear ownership -> Root cause: Shared responsibilities without SLA -> Fix: Define RACI and SLAs.
- Symptom: Secret scanning false positives -> Root cause: Test tokens similar to real tokens -> Fix: Maintain allowlist and patterns.
- Symptom: Overfocused on compliance -> Root cause: Checklist mentality -> Fix: Shift to risk-based decisions.
- Symptom: Long MTTR -> Root cause: Poor integration of tools -> Fix: Better playbooks and artifact linking.
- Symptom: Observability pitfall 1 — Low-cardinality metrics -> Root cause: Aggregation too early -> Fix: Increase cardinality where needed.
- Symptom: Observability pitfall 2 — Missing context in logs -> Root cause: No structured logging -> Fix: Adopt structured logging and enrichers.
- Symptom: Observability pitfall 3 — No correlation IDs -> Root cause: No tracing instrumentation -> Fix: Add trace IDs across services.
- Symptom: Observability pitfall 4 — Retention mismatch -> Root cause: Short retention for audit logs -> Fix: Adjust retention per compliance needs.
- Symptom: Observability pitfall 5 — Alert thresholds not adaptive -> Root cause: Static thresholds -> Fix: Use anomaly detection or dynamic baselines.
Best Practices & Operating Model
Ownership and on-call:
- Assign clear owners for security SLOs per service.
- Include security on-call rotation or a combined SRE-Sec rotation for escalations.
- Ensure handoffs and escalation paths are documented.
Runbooks vs playbooks:
- Runbook: Step-by-step technical remediation (automation friendly).
- Playbook: High-level decision flow and communication plan.
- Maintain both and version them in code where possible.
Safe deployments:
- Use canary releases with security checks on canary traffic.
- Implement automatic rollback on security regression.
- Gate high-risk changes with manual approvals and audit trails.
Toil reduction and automation:
- Automate repetitive detection and remediation.
- Use low-code automations with safe rollback and approvals.
- Prioritize automations by ROI and blast radius.
Security basics:
- Enforce MFA and strong credential hygiene.
- Rotate keys and use secret management.
- Apply least privilege and RBAC.
- Encrypt data in transit and at rest.
Weekly/monthly routines:
- Weekly: Review high-severity alerts and open remediation backlog.
- Monthly: Run tabletop exercises and review SLO status.
- Quarterly: Role-based training refresh and privilege audits.
What to review in postmortems related to Security Awareness:
- Root cause focused on human and process failures.
- Telemetry gaps that prevented detection.
- Whether automated remediation behaved correctly.
- Training or policy changes to prevent recurrence.
- Impact on SLOs and error budget use.
Tooling & Integration Map for Security Awareness (TABLE REQUIRED)
| ID | Category | What it does | Key integrations | Notes |
|---|---|---|---|---|
| I1 | SIEM | Central event correlation and alerting | Cloud logs IAM endpoints | Used for detection and reporting |
| I2 | CSPM | Detects cloud misconfigs | IaC CI registry | Good for cloud-first infra |
| I3 | Secret scanning | Finds credentials in code | Git CI chatops | Early prevention tool |
| I4 | Phishing platform | Simulates phishing exercises | Email providers LMS | Measures human risk |
| I5 | SAST SCA | Code and dependency scanning | CI IDE issue tracker | Shift-left fixes |
| I6 | DLP | Monitors sensitive data flows | Email storage endpoints | Prevents exfiltration |
| I7 | PAM | Controls privileged accounts | IAM directories SIEM | Reduces high-impact compromise |
| I8 | Observability | Logs metrics traces for SLOs | App infra CI | Core for detection and debugging |
| I9 | Orchestration | Automates remediation workflows | ChatOps ticketing | Enables safe automation |
| I10 | IR platform | Manages incidents and postmortems | SIEM chatops ticketing | Centralizes incident knowledge |
Row Details (only if needed)
- None
Frequently Asked Questions (FAQs)
What is the difference between Security Awareness and Security Training?
Security Awareness is the broader program combining telemetry, automation, and culture; training is a component focused on knowledge transfer.
How often should phishing simulations run?
Varies / depends; common cadence is quarterly for general staff and monthly for high-risk roles.
Can automation replace human judgment in security?
No; automation handles known, low-risk fixes. Human judgment is required for complex or high-impact decisions.
How do you balance privacy with behavioral telemetry?
Use anonymization, role-based access to telemetry, and legal/HR-reviewed policies for monitoring.
What SLIs are typical for Security Awareness?
Examples include phish click rate, MTTD, MTTR, secrets-in-commits rate; choose based on risk and telemetry quality.
How do you avoid alert fatigue?
Prioritize detections, tune thresholds, deduplicate alerts, and use runbooks for auto-triage.
Who should own Security Awareness in the org?
Shared ownership: Security teams lead, SREs implement technical telemetry, and product/HR support behavior change.
What is a reasonable starting target for remediation time?
Starting target: under 24 hours for misconfigs and under 12 hours for confirmed compromises; adjust to your risk profile.
How to measure training effectiveness beyond completion rates?
Measure behavior change via reduced phish click rates, fewer incidents from human error, and improved remediation times.
How do you handle false positives in secret scanning?
Maintain allowlists, refine patterns, and provide quick remediation guidance to engineers for valid cases.
When should security SLOs trigger deployment freezes?
If error budget burn doubles baseline within a short window or a critical security SLO breaches impact customer safety.
How to integrate Security Awareness into CI/CD?
Add policy-as-code checks, secret scanning, artifact signing, and gating steps that surface findings directly to developers.
Is AI useful for Security Awareness?
Yes for anomaly detection and coaching, but models require quality data and guardrails to avoid bias and privacy violations.
What are reasonable telemetry retention policies?
Varies / depends; balance detection needs and compliance. Keep high-fidelity data for critical assets longer.
How to prevent automation from creating new risks?
Implement staged rollout, human approvals for high-impact actions, and robust testing for remediation scripts.
How often should runbooks be updated?
After each incident and reviewed quarterly to ensure accuracy with current systems.
Can small teams implement Security Awareness effectively?
Yes; start with a focused scope (critical services) and scale iteratively with automation and measurement.
What budgets are typical for Security Awareness tooling?
Varies / depends; often allocated from security and platform budgets and tied to risk prioritization.
Conclusion
Security Awareness is a continuous socio-technical program that combines human training, telemetry, policy-as-code, and automation to reduce human-driven security risk. It requires clear ownership, measurable SLIs, and practical automation with safe rollbacks. Start small, instrument well, measure, and iterate.
Next 7 days plan:
- Day 1: Inventory critical assets and telemetry sources.
- Day 2: Enable or validate logs for cloud audit, CI, and app entry points.
- Day 3: Run a phishing simulation for a pilot group and collect baseline metrics.
- Day 4: Implement secret scanning in the main repo and block new secret commits.
- Day 5: Define 2 security SLIs and set realistic SLOs with error budgets.
- Day 6: Create a runbook for the top security alert and assign owners.
- Day 7: Schedule a tabletop exercise and a postmortem template for learnings.
Appendix — Security Awareness Keyword Cluster (SEO)
- Primary keywords
- Security Awareness
- Security awareness training
- Security awareness program
- Security awareness metrics
- Security awareness SLOs
- Cloud security awareness
- DevSecOps awareness
- Security awareness 2026
- Security awareness best practices
-
Security awareness automation
-
Secondary keywords
- Phishing simulation program
- Telemetry for security awareness
- SIEM for awareness
- CSPM awareness
- Secret scanning in CI
- Policy as code for security
- Security awareness dashboards
- Security runbooks and playbooks
- RBAC awareness
-
Least privilege awareness
-
Long-tail questions
- What is a security awareness program for cloud engineers
- How to measure security awareness with SLIs and SLOs
- How to integrate security awareness into CI CD pipelines
- Best practices for reducing phishing click rates
- How to create security awareness dashboards for executives
- How to automate remediation for misconfigurations safely
- What telemetry is needed for effective security awareness
- How to balance privacy and user monitoring in security programs
- How to set realistic SLOs for security behavior
-
How to run tabletop exercises for security awareness
-
Related terminology
- MTTD security
- MTTR security
- Error budget security
- Behavioral analytics security
- Security automation orchestration
- Zero trust awareness
- IAM hygiene awareness
- Secret management awareness
- Observability for security
-
Threat modeling awareness
-
Additional related phrases
- Cloud native security awareness
- Kubernetes security awareness
- Serverless security awareness
- Security awareness for SREs
- Security awareness incident response
- Security awareness postmortem
- Security awareness runbook
- Security awareness dashboards alerts
- Security awareness telemetry cost
-
Security awareness compliance integration
-
More targeted phrases
- Security awareness training for developers
- Security awareness measurement framework
- Security awareness automation best practices
- Security awareness metrics dashboard
- Security awareness phishing metrics
- Security awareness CI CD gates
- Security awareness secret scanning tools
- Security awareness for remote teams
- Security awareness policy as code examples
-
Security awareness integration map
-
Operational phrases
- Security awareness playbook examples
- Security awareness runbook template
- Security awareness error budget policy
- Security awareness alerting guidelines
- Security awareness dedupe strategy
- Security awareness on call rotation
- Security awareness blameless postmortem
- Security awareness tabletop exercise
- Security awareness chaos testing
-
Security awareness telemetry retention
-
Research and educational phrases
- Security awareness training modules
- Security awareness role based training
- Security awareness behavior change techniques
- Security awareness AI coaching
- Security awareness behavioral analytics tools
- Security awareness incident simulation
- Security awareness remediation automation
- Security awareness policy enforcement
- Security awareness benchmarking metrics
-
Security awareness continuous improvement
-
Industry-specific phrases
- Financial services security awareness
- Healthcare security awareness programs
- SaaS security awareness
- ECommerce security awareness
- Enterprise security awareness strategy
- Startup security awareness plan
- Government security awareness requirements
- Retail security awareness checklist
- Regulated industry security awareness
-
Cloud provider security awareness
-
Implementation phrases
- How to instrument for security awareness
- How to design SLOs for security
- How to build security awareness dashboards
- How to automate safe remediation
- How to write a security runbook
- How to measure phishing campaign effectiveness
- How to integrate SIEM and CSPM
- How to use policy as code for security
- How to run red team for awareness
-
How to conduct postmortems for security
-
Tooling phrases
- SIEM for security awareness
- CSPM tools for awareness
- Secret scanning tools for awareness
- Phishing platforms for awareness
- SAST tool integration for awareness
- DLP for awareness programs
- PAM for security awareness
- Observability tools for security
- IR platforms for awareness
- Automation orchestration for awareness



Leave a Reply
You must be logged in to post a comment.